
AI costs are easy to underestimate until agents, copilots, evaluations, and automated pipelines begin calling multiple models at once. Unlike a conventional API request, an LLM request does not map neatly to a predictable unit of work. Cost depends on the selected model, prompt size, generated output, retries, tool calls, and provider-specific token accounting.
Provider dashboards remain useful, but they are usually retrospective. Platform teams need an enforcement point that can stop runaway consumption before the next provider request is made. The gateway is a natural place to do that: every request already passes through it, so the gateway can attach trusted identity, reserve budget capacity, record actual token usage, and reject calls when an allocation is exhausted.
This post shows how to build a dollar-denominated AI cost-governance layer on top of agentgateway's native External Processing support. The reference implementation adds hierarchical budgets, pre-request reservations, actual-cost settlement, forecasting, approvals, rate limits, and a management UI.
The design follows four steps:
- Validate the caller and overwrite trusted identity headers.
- Reserve estimated budget before the LLM request leaves the gateway.
- Settle the reservation using provider-reported token usage.
- Alert, forecast, and optimize using real spend data.
The complete example used in this post, including deployment configuration and seed data, is available at github.com/day0ops/quota-management.
Native capabilities and the reference implementation
Before getting into the implementation, it is important to distinguish between the capabilities provided by agentgateway and the additional controls implemented by the example project.
Agentgateway provides the in-path extension point. Its External Processing support allows a gRPC service to inspect request and response traffic, mutate headers or bodies, and return an immediate response before traffic reaches an upstream provider. Solo Enterprise for agentgateway also provides native request and token rate-limiting patterns, along with LLM cost-tracking metrics.
The reference implementation in this post builds a richer dollar-denominated control plane on top of those capabilities.

For simpler use cases, native token budgets may be enough. The reference implementation becomes useful when teams need financial ceilings, delegated ownership, forecasting, and a clear approval trail.
Useful background reading:
Why AI spend needs gateway control
AI spend is not just another API bill. It is variable, fast-moving, and tied to behavior that can change from one request to the next.
Runaway agent loops
An agent that retries after an error or gets stuck in a tool-call cycle can send hundreds of requests in seconds. Each request may include an increasingly large conversation history. Without a hard stop, one bad loop can consume a team's monthly allocation before anyone sees an alert.
Context growth
A task that starts with a small prompt can grow into a large context window over a long session. Input and output tokens are priced differently, and output-heavy workflows can dominate the bill.
Multi-model sprawl
Teams often use OpenAI, Anthropic, Google, local models, hosted embeddings, and provider-specific fallbacks at the same time. Without per-team and per-model attribution, platform teams cannot tell whether a budget increase is justified or whether a cheaper model would do the job.
Blunt provider limits
Provider-side spend limits are useful as a final backstop, but they are usually account-level. They do not map cleanly to orgs, teams, users, projects, environments, or internal approval workflows.
Good budget control turns cost into an in-path policy decision. Requests carry trusted identity. Budgets are scoped to the organization. Usage is logged by model. Alerts and forecasts appear while there is still time to act.
A concrete customer scenario
Consider an organization called Acme with a monthly AI budget of $10,000.

A developer-facing copilot and a production support agent can share the same gateway while receiving different policies. If an evaluation job enters a runaway loop, the gateway rejects the next provider request when the $500 allocation is exhausted. The support agent remains unaffected because its traffic is charged to a different budget.
That is the key benefit of gateway enforcement: the control point is shared, but the policy is not blunt.
Architecture
The reference implementation has four main components:

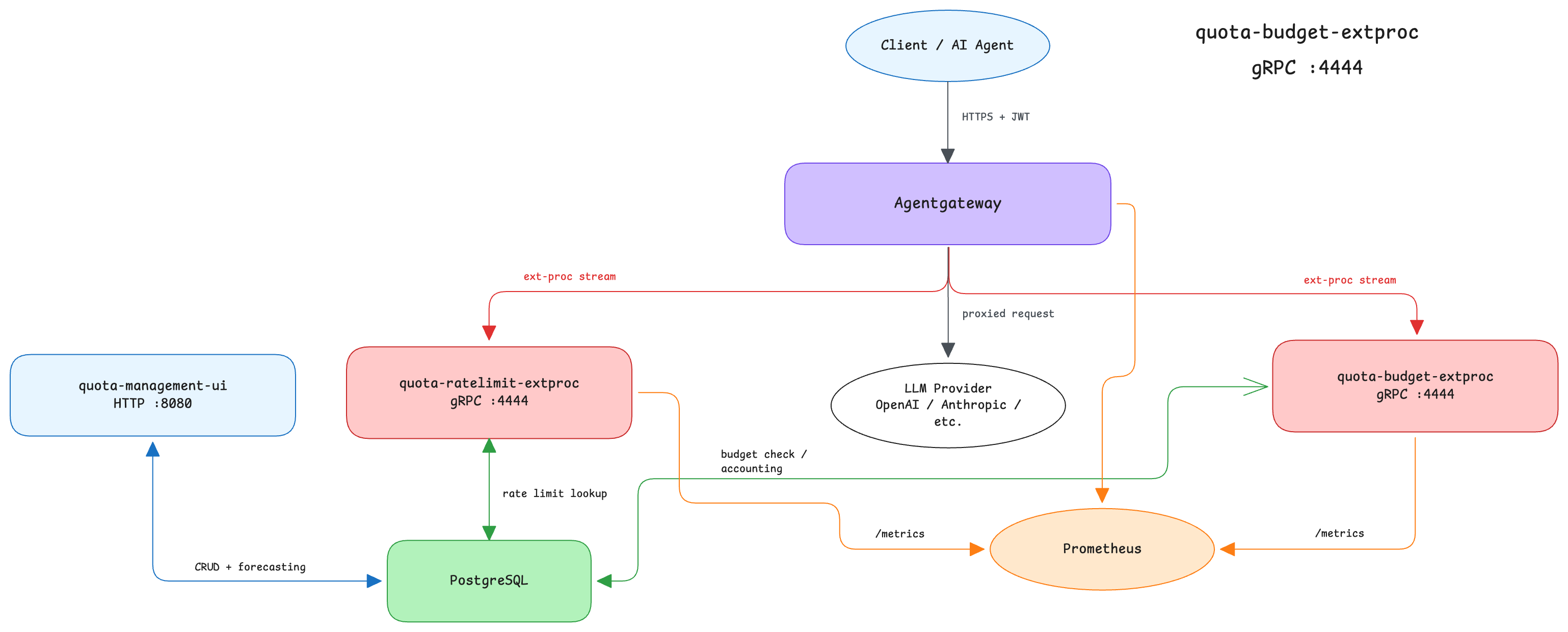
The budget service participates synchronously in the request path. This makes it suitable for enforcement rather than delayed reporting.
How enforcement works
Every LLM request passes through two budget stages:
- Pre-request reservation before the provider call begins.
- Post-response settlement after token usage is available.
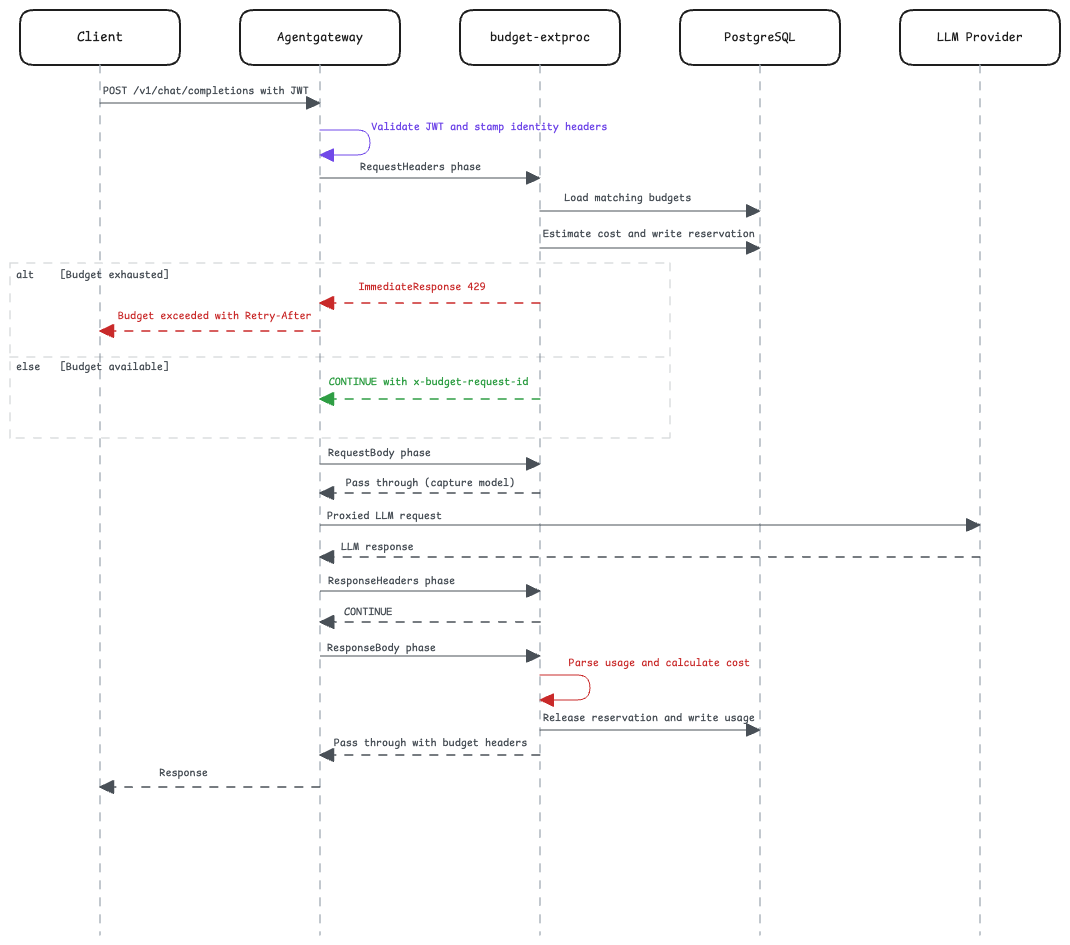
Why reservation and settlement are both necessary
An LLM request does not have a fully known cost before it begins. Output tokens depend on what the model generates. Prompt tokens may also be unavailable at the earliest enforcement point unless they are estimated or derived before forwarding.
A reservation prevents the gateway from allowing unlimited requests while waiting for actual cost data. Settlement replaces the estimate with the provider-reported usage after the response is complete.
Doing only one of these creates problems:
- Settlement without reservation allows concurrent requests to exceed the remaining budget before accounting catches up.
- Reservation without settlement blocks requests based on imprecise estimates and never records the true spend.
The enforcement decision belongs in RequestHeaders
The hard blocking decision is made during the RequestHeaders phase, before request-body streaming begins. Once body chunks have started moving upstream, returning a reliable immediate rejection becomes more complicated.
The gateway must therefore normalize the model name and attach trusted identity before invoking the budget ExtProc service.
A practical reservation strategy looks like this:

ExtProc phases
RequestHeaders
The service reads gateway-stamped request context such as:
x-gw-org-idx-gw-team-idx-gw-user-idx-gw-llm-modelx-gw-environmentx-gw-request-id- Optional metadata used for budget matching
It evaluates budget match expressions, estimates cost from the model-pricing table, and atomically reserves budget capacity.
There are two possible outcomes:
ImmediateResponsewith a configurable HTTP status when the budget is exhausted.HeadersResponsewithCONTINUEwhen budget is available.
RequestBody
The ExtProc service receives request-body chunks. It may reconstruct the body for validation, telemetry, or debugging, but the body should not be the primary hard-enforcement point.
Avoid persisting prompts unless there is a clear requirement. Usage metadata is generally enough for cost governance.
ResponseHeaders
Provider response headers pass through. The service may attach correlation metadata if needed.
ResponseBody
At end of stream, the service parses token usage, calculates actual cost, records usage, releases the reservation, and attaches response headers such as:
x-budget-cost-usd
x-budget-remaining-usd
x-budget-id
The parser handles common provider formats:

Calculating cost
Once token counts are extracted, cost is calculated using per-model pricing stored in PostgreSQL:
cost = (input_tokens / 1_000_000) × input_cost_per_million
+ (output_tokens / 1_000_000) × output_cost_per_million
For illustration, assume a small model costs $0.15 per million input tokens and $0.60 per million output tokens. A request using 500 input tokens and 800 output tokens costs:
(500 / 1_000_000) × 0.15 + (800 / 1_000_000) × 0.60
= $0.000075 + $0.000480
= $0.000555
The same formula applies during reservation, but the token counts are estimates. The implementation should use conservative defaults, requested output-token caps, and a configurable multiplier to reduce the risk of under-reserving.
Treat pricing as versioned configuration
Model prices change over time. Do not hard-code them into application logic.
Each usage record should store:
- Requested model ID
- Matched catalog model ID
- Provider
- Input and output token counts
- Input and output unit prices applied at settlement time
- Total cost
- Pricing-table version or effective date
- Match strategy, such as
exact,normalized, orfallback
This makes historical usage auditable even after prices change.
Identity and the trust boundary
Every request carries a JWT issued by an identity provider. Agentgateway validates the token before routing and overwrites trusted headers for ExtProc.
The important word is overwrites. The gateway must never trust identity headers supplied by the client.
An illustrative transformation looks like this:
yamltransformation:
request:
set:
- name: x-gw-org-id
value: "jwt['org_id']"
- name: x-gw-team-id
value: "jwt['team_id']"
- name: x-gw-user-id
value: "jwt['sub']"
The exact policy resource depends on the agentgateway deployment mode and version. The principle remains the same:
- Validate the JWT.
- Remove or overwrite caller-provided identity headers.
- Normalize the model name.
- Attach a correlation ID.
- Invoke ExtProc only after the request context is trusted.
Use a small, consistent set of fields:

Keep these fields boring, consistent, and visible. Then build dashboards that answer who spent money, on which model, in which environment, and why.
Budget model
Budgets are scoped to orgs, teams, and users.
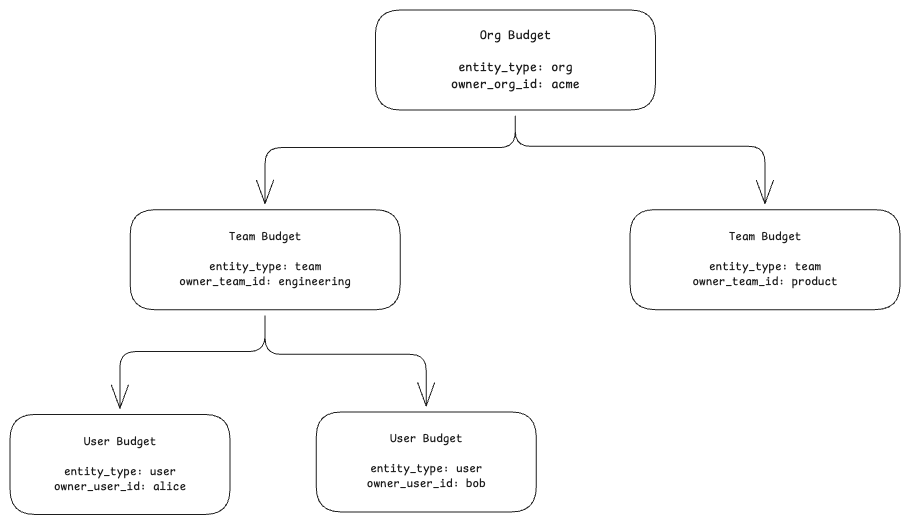
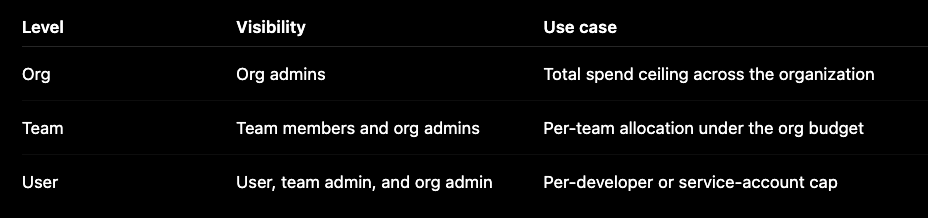
Each budget has a CEL match expression. A budget can match on org, team, user, model, request headers, gateway metadata, or any combination.
Isolation and fallback
Child budgets support two useful behaviors.
Isolated budgets are hard caps. If an isolated team budget is exhausted, the request is rejected even when the org budget still has capacity. Use this for sandbox environments, test pipelines, or projects that must not exceed their allocation.
Fallback budgets can draw from the parent when the child is exhausted. If the team budget is empty but the org budget has room, the request is allowed and the usage record marks parent_charged: true. If the parent is also exhausted, the request is rejected.
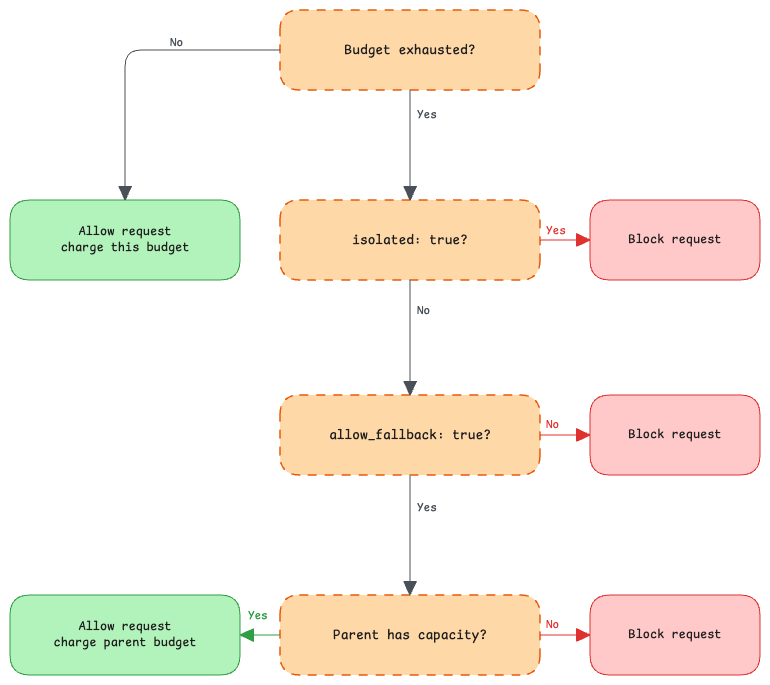
Periods and retry behavior
Budgets can reset hourly, daily, weekly, monthly, or on a custom interval. A background worker resets expired budgets by clearing period counters and advancing current_period_start.
Rejected responses should include a machine-readable body and, where appropriate, a Retry-After header containing the number of seconds until reset.
Example rejection:
{
"error": "budget_exhausted",
"budget_id": "engineering-monthly",
"scope": "team",
"remaining_usd": "0.000000",
"resets_at": "2026-07-01T00:00:00Z",
"message": "The AI budget for this team has been exhausted. Stop the current task and surface this error to the user."
}
The status code should be configurable because automated clients do not all handle retryable errors in the same way.
Approval workflow
Budget creation requires approval before enforcement. New budgets start in pending state. Org admins can approve or reject budgets in their org. Team admins can manage budgets within their permitted scope.
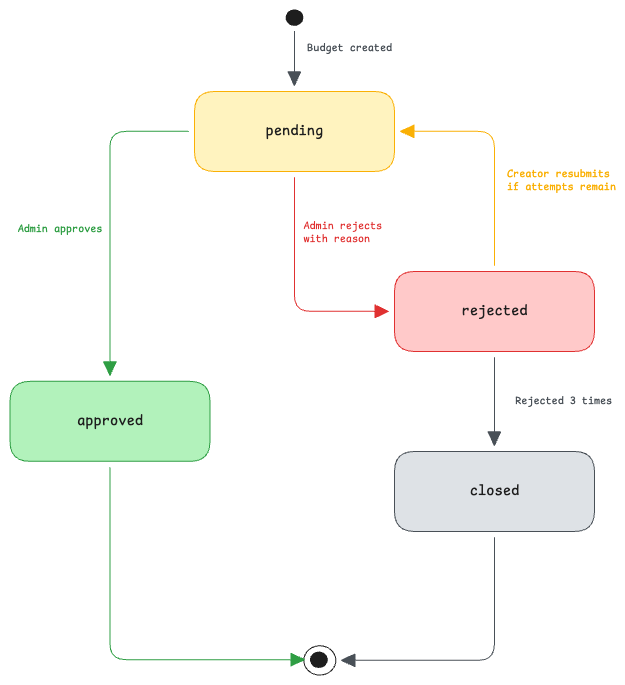
Rejections should require a written reason. Resubmissions should remain auditable. The same workflow can apply to rate-limit allocations.
Here's an example of the budget approval workflow on the management UI:
Admin roles and permissions
The management API enforces role-based access at every write operation.

Only org admins should be able to expand budgets that sit under an organization ceiling. This prevents teams from quietly increasing their own allocation without an approval trail.
Model pricing and unknown models
The ExtProc service stores model prices in PostgreSQL. Each record contains input and output cost per million tokens. Optional fields cover cache-read and cache-write pricing for providers that support prompt caching.
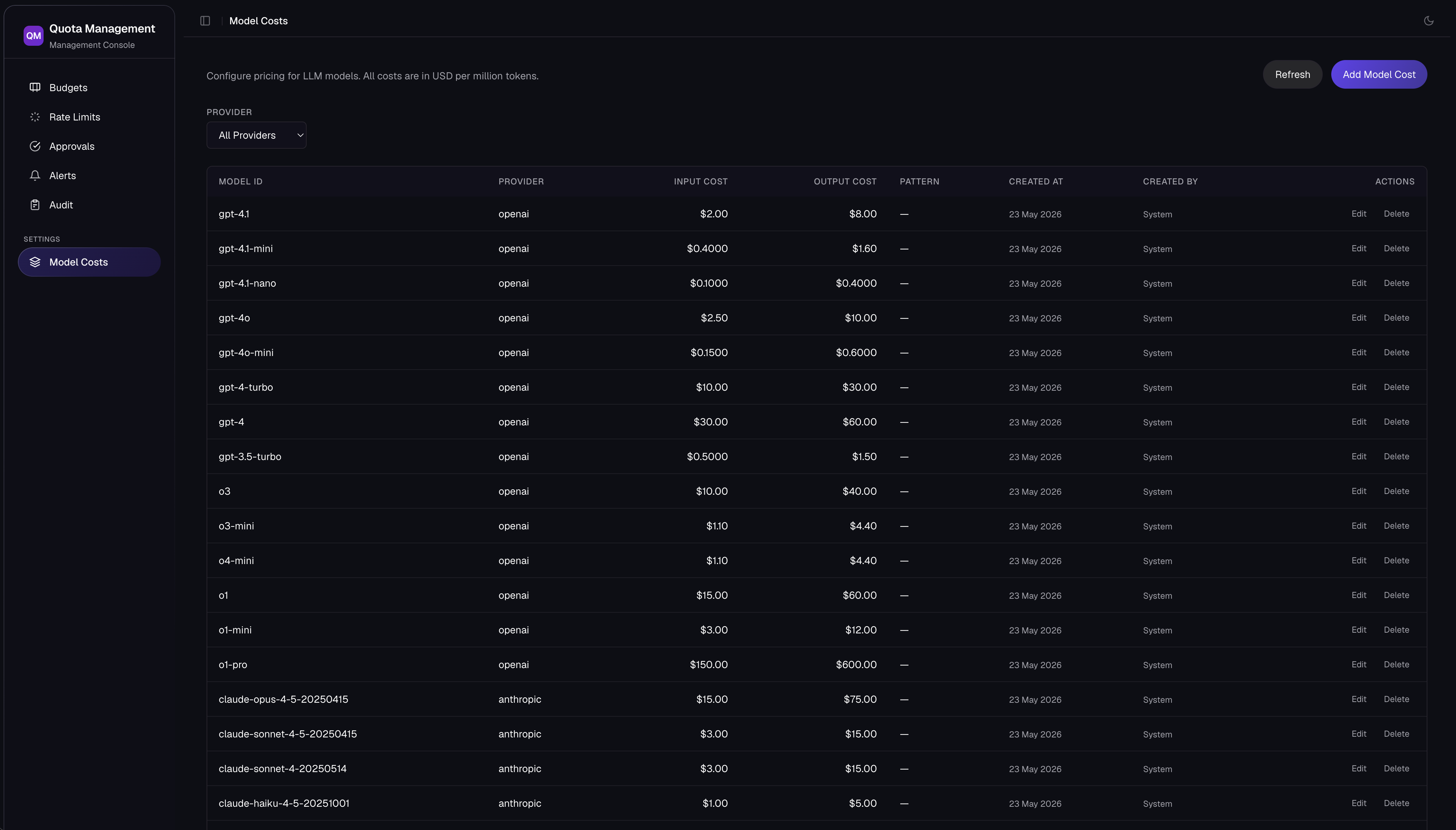
Model lookup may normalize provider-specific version suffixes. For example, a dated model identifier may be matched to a stable pricing-catalog entry. Any fuzzy or normalized match must be auditable.
Use a safe unknown-model policy
An unknown model should not silently inherit an optimistic default price in production. That can allow an expensive new model to consume more budget than expected.
Make the behavior configurable:

Log the requested model ID, matched catalog key, match strategy, and applied rate for every request.
Production hardening
A synchronous enforcement service becomes part of the critical request path. The failure policy must be deliberate.
Agentgateway supports failClosed and failOpen behavior for ExtProc failures. For governed LLM routes, prefer failClosed: if the budget service cannot make a reliable decision, block the request rather than silently bypassing controls.

Security guidance
ExtProc can inspect request and response bodies. In an LLM gateway, those bodies may include prompts, generated content, tool inputs, and sensitive data.
Use these controls:
- Encrypt traffic between agentgateway and the ExtProc service.
- Do not store raw prompts or responses unless there is a clear requirement.
- Store usage metadata separately from content.
- Redact secrets from application and audit logs.
- Restrict management UI access through OIDC and role-based authorization.
- Store PostgreSQL credentials in Kubernetes secrets or an external secret manager.
- Audit budget, role, and model-pricing changes.
- Set retention periods for usage records and audit logs.
Operating the system
Once enforcement exists, day-to-day work shifts to visibility, forecasting, and optimization. Operators need to know which budgets are healthy, which teams are trending toward exhaustion, and where model choices can be improved.
Alerts and forecasting
The management UI calculates budget health continuously:

Four alert types fire automatically:

Forecast alerts fire before exhaustion. A budget with a $10 daily limit that has spent $2 in the first hour should trigger a warning immediately, long before the hard cap is reached.
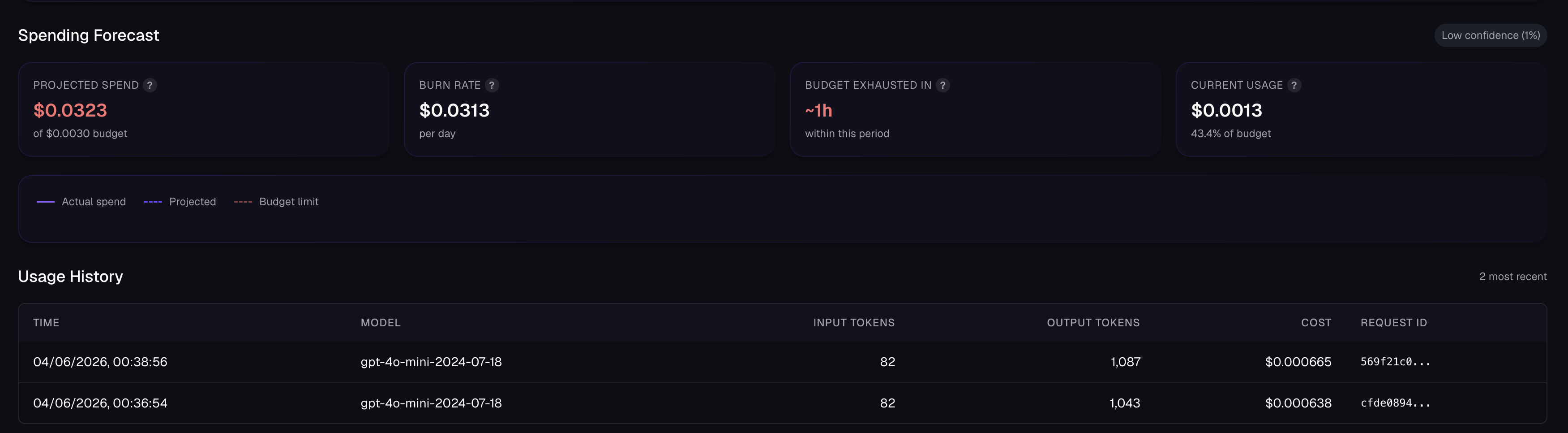

A practical policy is:
- Alert owners at
60%usage. - Escalate at
85%when burn rate still points to exhaustion. - Enforce at
100%and disable or degrade noncritical paths.
Budget detail and management UI
Each budget has a detail view showing current usage, limit, remaining capacity, reset period, hierarchy flags, and usage history.
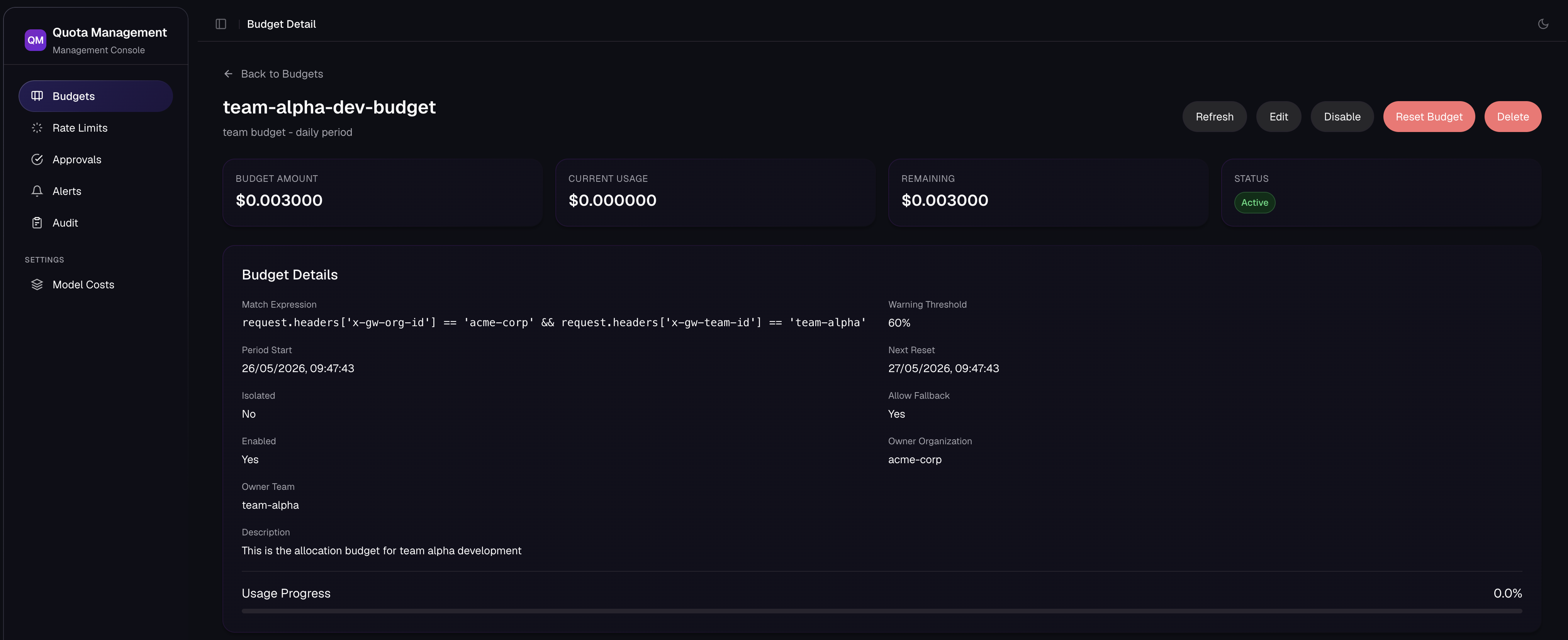
The UI gives operators one place to manage:
- Budget status and hierarchy flags.
- Request-level usage history with concrete model IDs and token counts.
- Forecasting based on real burn rate.
- Threshold and exhaustion alerts.
- Per-user and service-account assignments.
- Approval queues.
- Audit logs containing actor, action, timestamp, and metadata.
- The model-pricing catalog.
The UI is intended for shared ownership. Platform teams enforce global controls, while team owners inspect their own usage and justify changes with data.
Observability
The budget service exposes Prometheus metrics on port 9090.

These metrics integrate with Prometheus and Grafana without requiring every application team to add custom instrumentation.
Complement budgets with rate limits and token caps
A spend budget limits cumulative financial exposure. It does not replace rate limiting.
A runaway agent can still generate a burst of concurrent requests before settlement catches up. Layered controls reduce that risk.

The reference implementation includes a separate quota-ratelimit-extproc service. Rate-limit allocations can be scoped per org, team, and model pattern.

Start new allocations in monitoring mode, observe real traffic, and switch to enforced after calibrating the limits.
You can also centrally cap provider request fields such as maximum output tokens or reasoning effort through gateway transformations. That reduces the worst-case cost of an individual request before it reaches the model provider.
Minimum adaptation path
The repository contains the full deployment manifests and seed data. The following sequence gives customers a practical mental model for adapting the design.
1. Deploy the data store
Deploy PostgreSQL and create tables for:
- Budgets
- Reservations
- Usage records
- Model prices
- Alerts
- Approval requests
- Audit records
2. Deploy the budget ExtProc service
Configure the service with:
- PostgreSQL connection details
- Reservation TTL
- Estimation defaults and multiplier
- Unknown-model policy
- Budget-exceeded status code
- Pricing-cache TTL
3. Validate identity at the gateway
Configure JWT validation and overwrite the trusted context headers:
x-gw-org-id
x-gw-team-id
x-gw-user-id
x-gw-llm-model
x-gw-environment
x-gw-request-id4. Attach ExtProc with a fail-closed policy
Use the ExtProc policy supported by your agentgateway deployment mode. Verify that requests fail safely when the budget service is unavailable.
5. Seed model prices
Add the model IDs used by your organization. Include provider-specific variants, cache pricing where relevant, and an explicit unknown-model policy.
6. Create initial budgets
Start with a small number of easy-to-understand allocations:
- One organization budget
- One isolated sandbox budget
- One production team budget with controlled fallback
- One service-account budget for automated evaluations
7. Test allowed traffic
Send a request with a valid token and verify:
- The upstream provider receives the request.
- The usage record includes the org, team, user, model, and request ID.
- The reservation is released after settlement.
- The cost response headers are attached.
8. Test rejection behavior
Exhaust a small test budget and verify:
- The provider is not called.
- The gateway returns the expected machine-readable error.
- The client behavior is acceptable.
- Alerts and audit records appear.
9. Test failure modes
Deliberately stop the ExtProc service and PostgreSQL in a non-production environment. Confirm that the gateway follows the intended fail-closed policy and that orphaned reservations are reconciled.
Example: Claude Code through the gateway
The same enforcement path applies to developer tools and production services. Anything routed through agentgateway receives the same identity, budget checks, accounting, and telemetry.
Claude Code supports routing through an LLM gateway by setting a custom Anthropic-compatible endpoint and bearer token:
export ANTHROPIC_BASE_URL="https://<gateway-host>"
export ANTHROPIC_AUTH_TOKEN="<gateway-issued-token>"
The gateway endpoint must expose the Anthropic Messages-compatible API expected by Claude Code. The bearer token reaches agentgateway as an Authorization: Bearer header and can be validated before the request is forwarded.
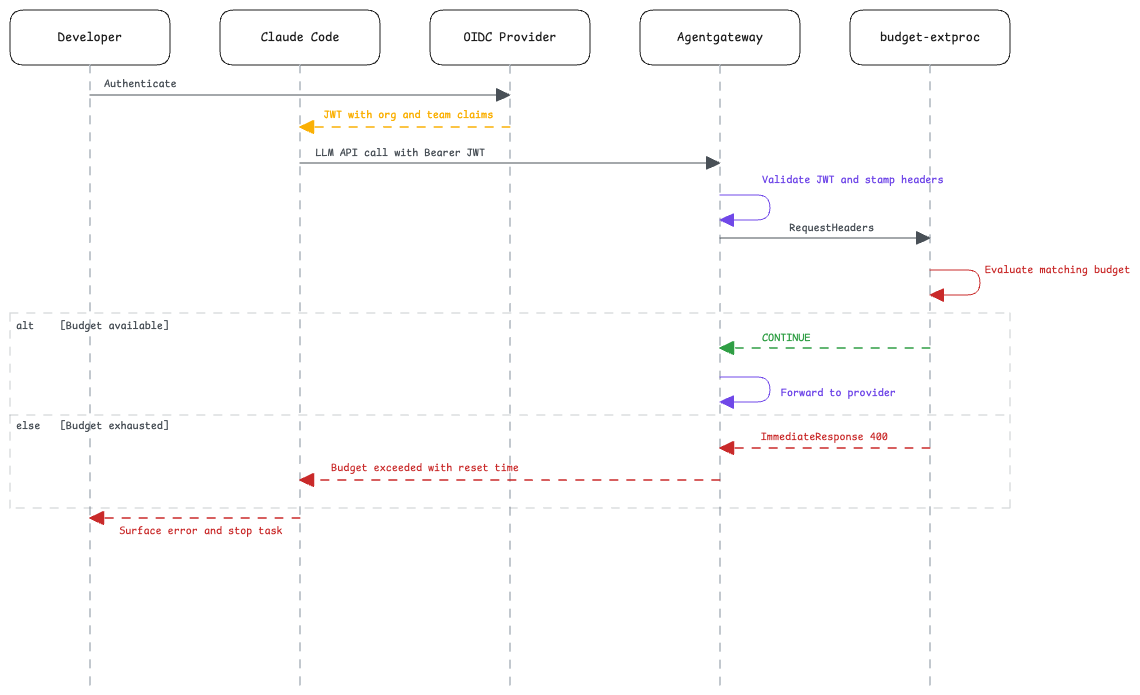
From the operations side, Claude Code usage appears beside other LLM traffic in the same UI. There is one budget model, one forecast, and one audit trail.
Validate retry behavior for your client version
Do not assume every client handles budget exhaustion in the same way. A 429 Too Many Requests response is useful when a retry after reset is appropriate. A permanently exhausted task may require a non-retryable response so the client stops and surfaces the error.
Make BUDGET_EXCEEDED_STATUS_CODE configurable and test the behavior against the Claude Code version deployed in your environment. Client retry behavior can evolve over time.
Optimization after enforcement
Once cost is visible and bounded, teams can optimize safely.
Route by task shape
Use smaller models for extraction, classification, formatting, and other structured outputs. Save large, long-context, or reasoning models for work that actually needs them.
Shadow cheaper models
Send a small percentage of traffic to a cheaper candidate model while logging quality and cost. Expand only when acceptance rate and latency hold up.
Cache repeat work
Cache stable prompts, normalized parameters, and deterministic tool outputs. Track cache hit rate next to cost per request.
Track model usage
Record usage by concrete model ID so operators can detect when a workflow begins using a more expensive model than expected. For broader grouping, use model naming conventions or patterns in the pricing catalog.
The operating sequence is straightforward:
- Unify request identity and usage logging.
- Apply budgets and rate limits.
- Observe actual traffic.
- Improve routing with evidence.
Summary
Gateway budget control gives teams enforcement instead of delayed reporting. Agentgateway provides the in-path External Processing integration point. The reference implementation builds on that foundation by reserving estimated cost before the provider call, settling actual usage after the response, and tying spend to trusted identity and model data.
The most important design principles are:
- Validate identity and overwrite trusted context headers at the gateway.
- Reserve budget before forwarding the provider request.
- Settle with provider-reported token usage.
- Version model pricing and reject unknown models safely.
- Combine budgets with request limits, token limits, and per-request caps.
- Fail closed when the cost-control service cannot make a reliable decision.
- Test client retry behavior rather than assuming it.
That combination gives finance a clear ceiling, gives platform teams a shared control point, and gives application teams enough visibility to choose cheaper models, cache repeated work, and request budget increases with evidence.
Learn more about agentgateway
- Get started with agentgateway
- Check out the project on GitHub
- Join the community on Discord
- Learn more on the website







%20(1).png)




















%20a%20Bad%20Idea.png)








