
In previous posts, I’ve covered the reasons why an AI agent needs an identity. I recommend reading that first. In this post I want to nail down “what is agent identity” because I’ve seen a lot of different interpretations from smart people such as “use OAuth” to “it’s just workload identity”, and new protocols cropping up, etc. But what “is” an agent identity in concrete terms?
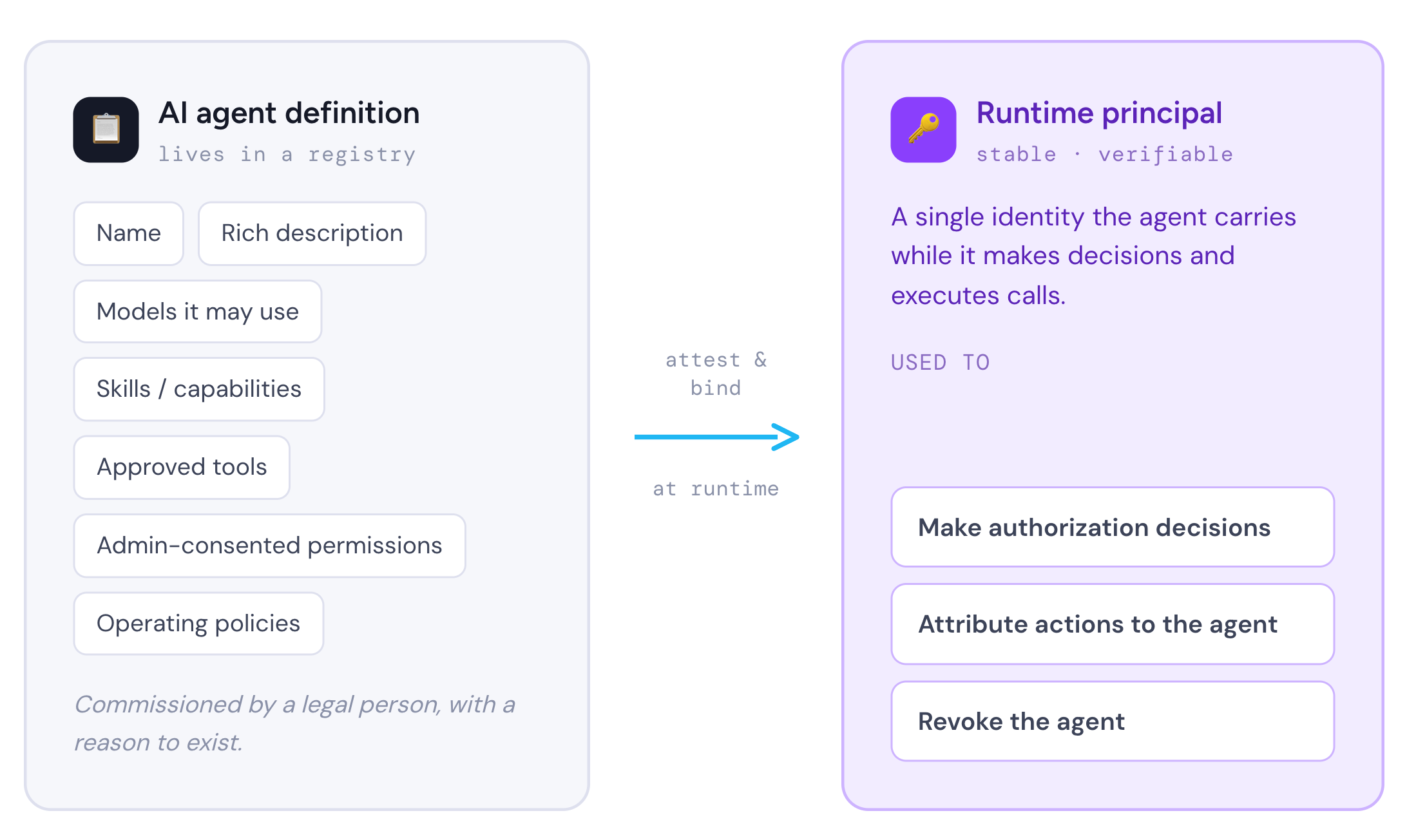
An AI agent is something a legal person commissions with a reason for existence e.g., an expense-report agent, supply-chain optimizer, personal assistant, etc. It can be described with a name, rich description, models it may use, skills/capabilities it offers, approved tools, admin-consented permissions, and the policies it operates under. Those details live in a registry somewhere. But at runtime, when the agent is making decisions about how to accomplish a task and actually executing calls, we need a stable, verifiable principal. This principal is used to make authorization decisions, attribute actions to the agent and lastly to revoke an agent. How do we get from the rich definition of an AI agent to verifiable runtime identity?
Are Agents like Humans? Like Workloads?
Agents are not human. Giving them human identities would give them the standing of a human with none of the built-in human-ness/constraints. Agents kinda look like workloads, so something like service account or workload identity may be appropriate here, but agents don’t exhibit the behavior we typically see from workloads and that’s something we’ll need to work through.
Should an agent identity be a “new thing”, i.e, a layer on top of workload identity? Or can we just use existing workload identity?
The answer to both questions simultaneously is “yes” …. but how can that be?
Agent Identity as Workload Identity
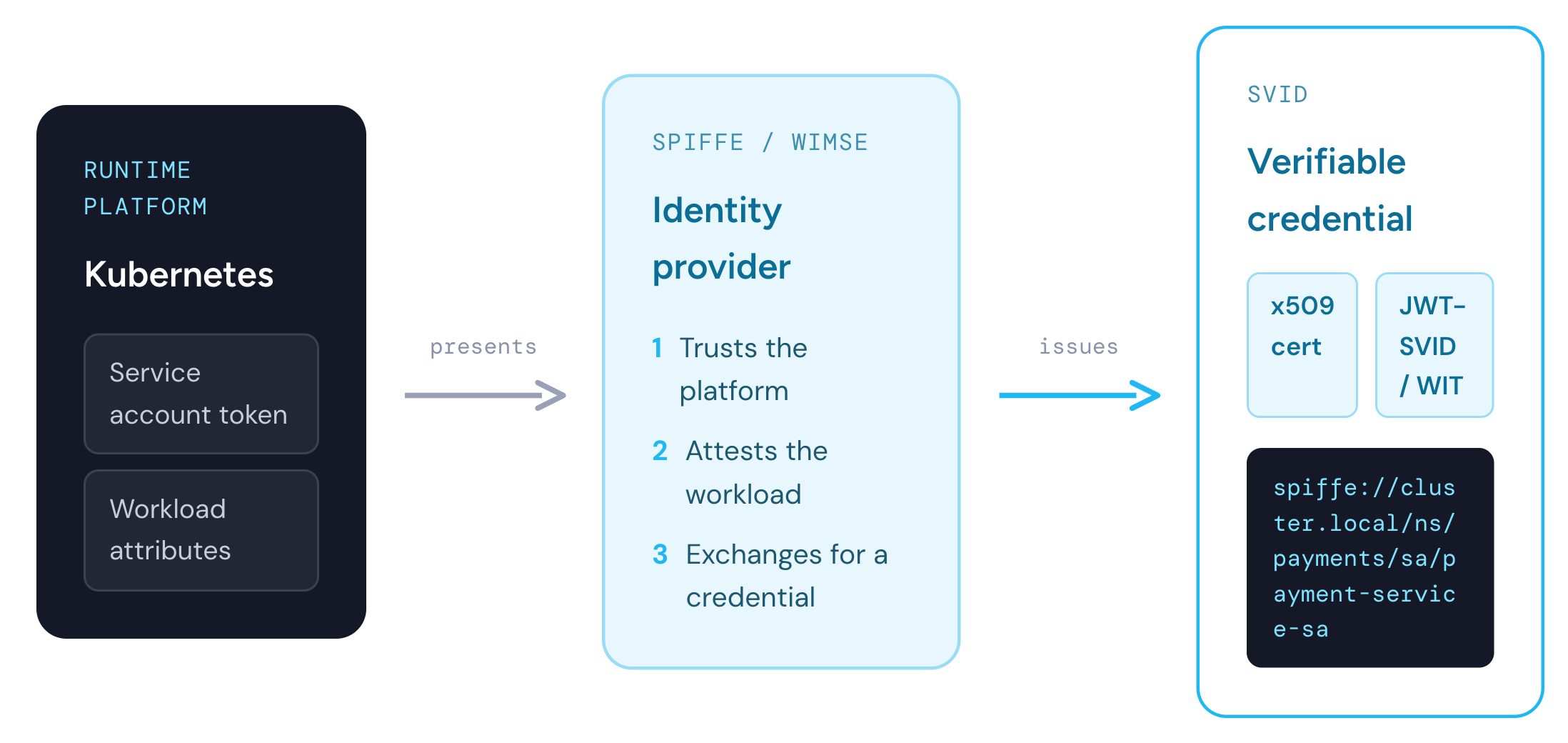
The truth is, an AI agent “is” an executable piece of software. It runs somewhere. If you look at what identity primitives are available in common execution environments (Kubernetes, containers in general, VMs, etc) some form of workload identity is usually available. SPIFFE/WIMSE is a form of workload identity and is a natural fit. SPIFFE implementations attest a running workload using attributes of the workload, trusting its runtime platform, and then issuing an x509 certificate or JWT-SVID/WIT. For example, in Kubernetes, it’s a common practice for a SPIFFE implementation to trust the Kubernetes platform, service account tokens, and exchange those for SPIFFE credentials.
For a microservice (ie, payment-service with SPIFFE ID spiffe://cluster.local/ns/payments/sa/payment-service-sa) the deployment itself is the binding. A microservice gets deployed 1:1 with a pod (ie, one service per pod), may scale up/down its replicas, and each replica is exactly the same as the next. Any time a payment-service Pod gets scheduled, it will have the same stable and cryptographically verifiable identity as determined by the runtime attestations and SPIFFE.
How does this work for AI agents? If you deploy your AI agent 1:1 with a Kubernetes Deployment (ie, Pods), then this “workload identity == agent identity” probably works fine. This is what the Uber team recently shared with us. In fact, this is also how the kagent open-source project is built. Think of kagent as like AWS Agent Core but for Kubernetes-native deployments on any Kubernetes/cloud. In kagent, an agent is a single deployment, with a stable identity based on SPIFFE (from Istio Ambient Mesh), and all agent executions, user contexts, memory, etc is handled by the agent framework within those worklods. The binding is owned by the agent runtime (kagent in this case).
But the reality is, an agent doesn’t have to be bound to a specific workload.
The challenge is, in practice, AI agents don’t behave like long-lived server/microservice workloads. They are bursty. They are ephemeral. They churn across workloads/clusters/clouds. They pause/resume. They spawn sub-agents or tools. And in the kagent community, we have experienced pressure from our users to pursue more light-weight alternatives to Kubernetes Pods, and to bind executions for individual users in more hardened execution environments (sandboxing).
This starts to look like “actors” more than Kubernetes pods.
With a model like this, actors have an agent identity that starts to look like a layer on top of workload identity.
Agent Identity as a Separate Layer
Let’s look at a concrete example. At Solo.io, we recently contributed to kagent support for a new actor sandboxing projectreleased by Google, called agent substrate. Agent substrate solves some of the aforementioned pressure from kagent users. I’ll give a quick overview here, but it may be useful to review the agent substrate architecture docs or a companion deep-dive learning site.
Agent substrate uses two Kubernetes custom resources (CRs) and implements a new control layer on top of Kubernetes. The WorkerPool CR defines a template for what a set of generic pre-warmed “workers” (pods) looks like. The ActorTemplatedefines what an agent/actor “class” looks like. At runtime, agent substrate schedules actor “instances” (from the AgentTemplat) wrapped in hardened sandboxes (Firecracker/microVM/gVisor/etc) into the pre-warmed workers. These actors align with the lifecycle of an AI agent including bursty-ness/pause/suspend, etc. Substrate can snapshot the actor’s entire sandbox/memory to durable storage. It can then remove the actor from the workload when they suspend which clears the worker for another actor to be scheduled/resumed into. Substrate tracks this actor:worker mapping in its registry which is able to handle millions of suspend/resume operations and boot actors significantly faster that what the Kuberentes control plan can for pods. This model allows to run orders of magnitude more actors/agents than workers by multi-plexing them into worker pods at runtime.
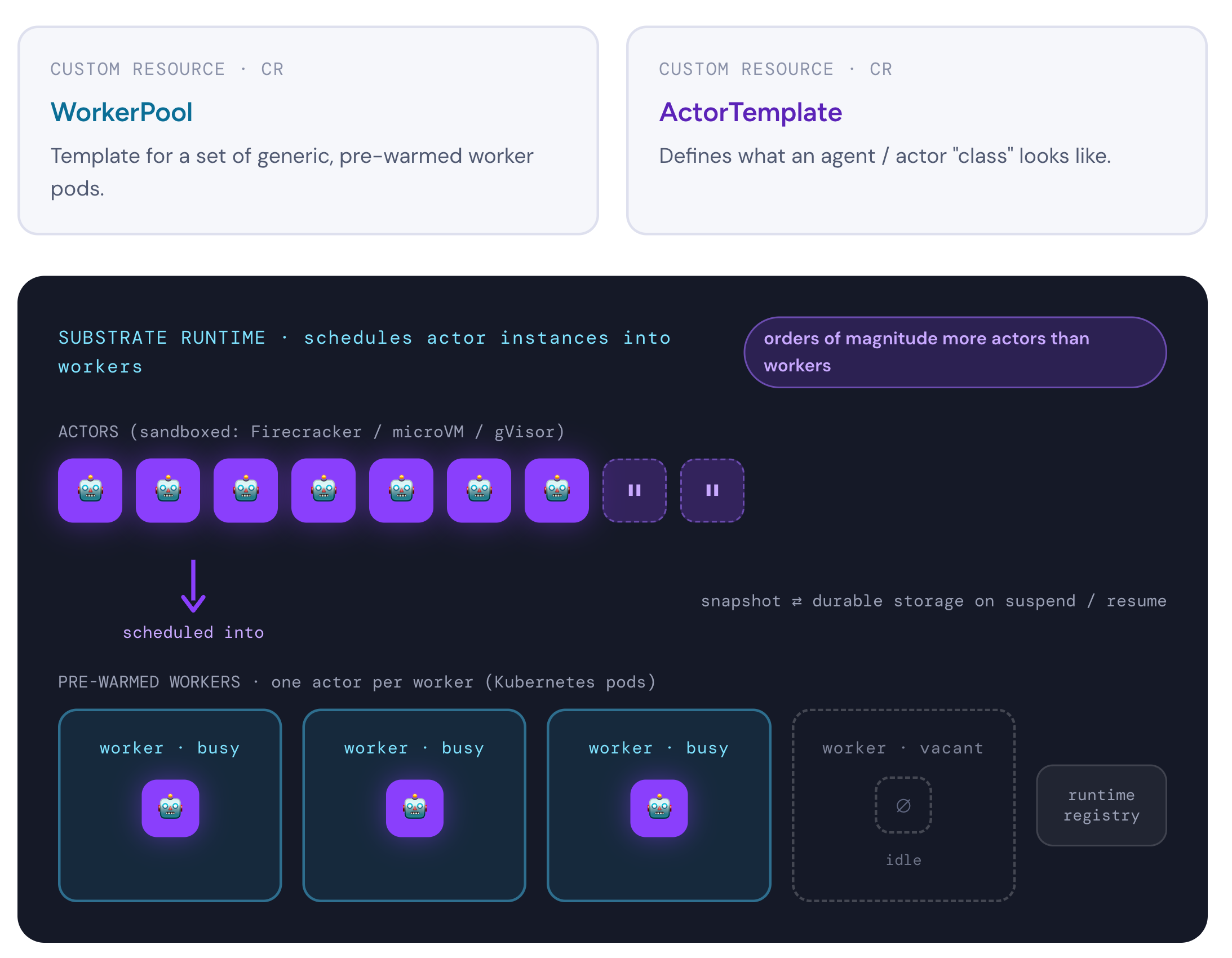
The “worker” pods carry a workload identity such as spiffe://cluster.local/ns/substrate/sa/worker-pool-defaultbut that does not represent the running agent or actor. The workload identity may still be useful for traffic authorization policy (ie, “only traffic originating from worker-pool pods for these endponts is allowed”), but it tells you nothing about the specific agent or actor.
Each of the actors will need an identity that gets bound to them at schedule time (ie, when it is brought back to life within a worker). For example, spiffe://substrate.local/ns/substrate/actortemplate/actor-foo/actor/actor-id-xyz, and remains the same throughout the lifecycle of the actor/agent. Each time the actor/agent gets scheduled/paused/resumed, it must continue with the same identity. The binding between the actor and the actor’s identity would be maintained by agent substrate’s runtime registry. It would maintain the continuity of identity for all actors.
So if you squint with your right eye, this looks like a separate agent-identity layer on top of workload identity. But, if you ask “well, isn’t this still workload identity attested to the micro VM level”? Then you squint with your left eye, and this looks like a more-fine grained workload identity … but workload identity none-the-less.
And what you’re seeing through both eyes is correct.
If you own the infrastructure, within a trust domain and can control the following invariants, you can collapse agent identity into workload identity:
- One-to-one mapping agent/actor to workload
- A registry which maps agents/actors to workloads at runtime; becomes the identity source of truth
- Agent/actor identity continuity across restarts/resumes/reschedules regardless of workload
Otherwise, agent identity will feel like a layer on top of workload identity.
Note: Before we continue, we have to be careful, because two different identities are in play and they answer two different questions. There's the identity of the actor class (what the ActorTemplate defines) and the identity of a specific scheduled instance of that class (actor). The first is what you write policy about. The second is what you attribute a runtime action to. Collapsing them is the mistake, because you cannot enumerate, catalog, or pre-author policy against identities that don't exist until schedule time and disappear on suspend. One subtlety worth stating explicitly: per-instance context can narrow what an actor may do, but never widen it. A scheduled actor runs on behalf of a specific user and session, so its effective permission is the intersection of what `actor-foo` is permitted as a class and what this user delegated for this session. The agent identity sets the ceiling; the actor identity carries the runtime narrowing. The moment you let an instance grant itself something its template doesn't have, you've collapsed the layers in the wrong direction and lost the property that made the class identity worth cataloging in the first place.
Other Examples?
This pattern of “an agent/worlkoad identity on TOP of workloads” is not unique to what we feel in the kagent and agent substrate projects. In fact it’s a very common pattern across implementations.
Agent Core does something similar to what kagent/substrate except that AWS owns the complete stack. When you deploy an agent to Agent Core, it runs in a container in a hardened sandboxed microVM (Firecracker?). Under the covers, this sandbox has a real “workload identity” similar to the substrate worker pod, but in Agent Core, this workload is never exposed directly to the user (it’s probably used for AWS tenant isolation and underlay policy enforcement). In fact this underlying workload could churn (e.g. every 900s if inactive) but you don’t see it because what you see is the Agent’s “workload ARN”. What Agent Core calls “workload identity” in its docs is not really the microVM/sandbox, it’s the singular agent ARN such as:
arn:aws:bedrock-agentcore:us-west-2:111122223333:workload-identity-directory/default/workload-identity/my-agent-a1b2c3d4e5
Yes it has the word “workload identity” in it, but it’s really a more stable identity that continues along with an Agent Core agent regardless of what underlying container/microVM it runs in. You can even get this Agent identity through the Metadata Service running within the microVM – it’ll be the agent’s identity, not the container’s workload identity. The point here is: it’s a layer on top of the underlying infrastructure and, critically, the Agent Core control plane maintains the mapping and issuance/attestation and continuity of identity to the runtime. This all lives within a single system (ie, AWS), built on AWS’s IAM mechanisms.
Microsoft Entra Agent ID is also a layer on top of the workload. I’ve written a significant mutli-part “Entra Agent ID on Kubernetes” series of posts. I highly recommend reviewing that. In this case, Entra Agent ID is an extension of Entra ID (ie, it’s a specialized service principal) and lives nicely within a single system (ie, Microsoft) built on Microsoft’s IAM mechanisms (Entra). It can be federated with workload identity but is itself a separate thing.
Lastly, we see a new protocol Agent Auth (AAuth) from Dick Hardt which introduces a cloud-agnostic agent identity model(along with dynamic discovery, person-based delegation and auth, rich resource definitions, mission intent, built with no bearer tokens). This is also built as a layer on top of workload identity, but just like Entra Agent ID, can integrate nicely with workload identity to bootstrap agent identity.
It’s a Separate Layer, Can be Collapsed. Until it Can’t.
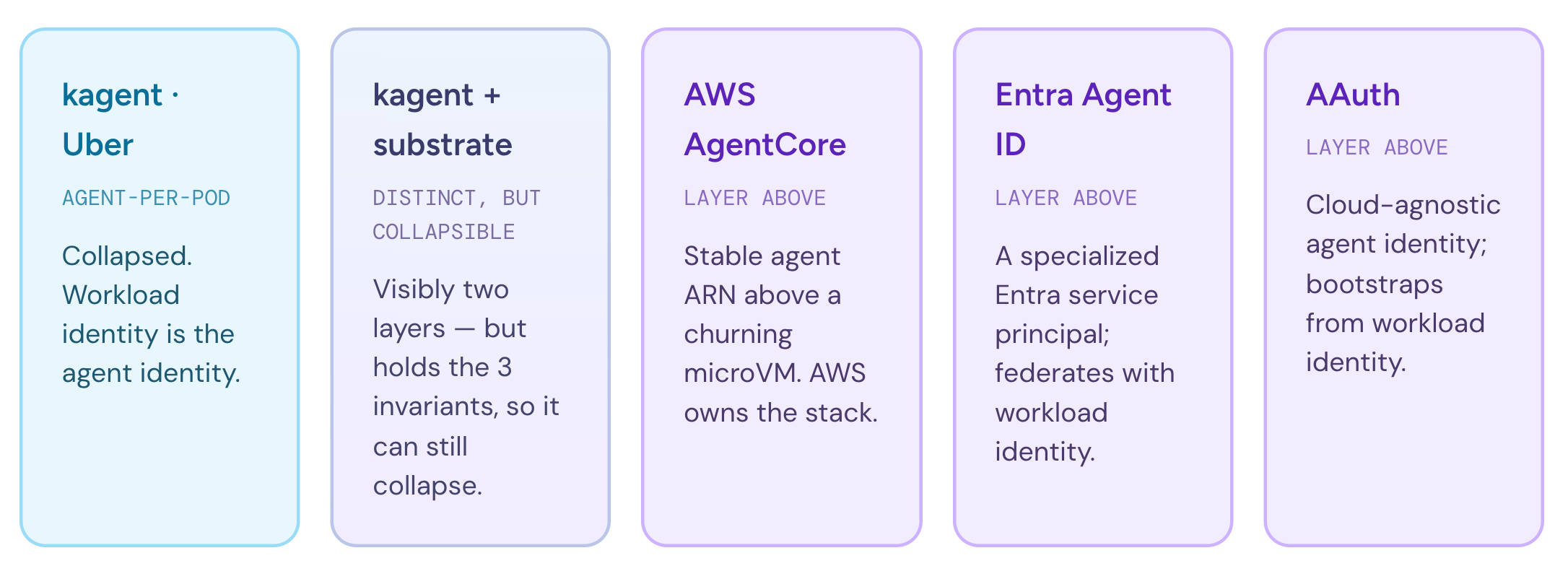
Let’s call out the main point clearly: In agent-per-pod scenarios, like in Uber’s architecture or kagent, we see workload identity and agent identity collapse. With kagent+substrate the layer is visibly distinct, but since it holds to the three invariants (1:1, registry, continuity), you can still collapse to workload identity (its an available mental model, but not “automatic”). In the AgentCore/Entra/AAuth examples, the agent identity is a layer above the running workload identity.
What every one of these examples, except AAuth, shares: a single control plane maintains that continuity, inside a single trust domain. The harder problem starts the moment an agent has to act somewhere its issuing platform doesn’t reach. Agents are more and more given access to registries where they can discover tools, APIs, and other agents. The more we build for an open-ecosystem of AI agents, and expand beyond a single-trust domain, integrating across organizations/trust boundaries, the more the invariants for workload==agent identity start to strain. In the next blog post, we take a closer look at agent identity in an open ecosystem, how workload identity plays, and what options we have. Follow this blog / connect with me on LinkedIn if interested in this topic.








%20(1).png)




















%20a%20Bad%20Idea.png)








