
Architects rarely set out to run supersized clusters. They start with something right-sized, then watch it swell: more and more microservices, an operator here, a logging stack there. Before long, the platform is groaning under its own weight.
At first, keeping “everything in one cluster” feels simpler:
- No cross-cluster DNS puzzles
- No overlapping-CIDR headaches
- No mTLS between trust domains
- One ingress, one egress path, one place to debug traffic
But that simplicity is an illusion. Once a cluster grows,, every hidden networking edge case emerges, and usually at the worst possible moment. Performance stalls, security boundaries blur, and the failure domain covers your entire company.
These hidden complexities are the exact reason why many organizations hit an invisible wall as their clusters grow. Over the last few years, we’ve observed common pain points and systemic issues that stem directly from pushing a single Kubernetes cluster beyond its intended scope. These issues manifest across various layers of the stack:
The Invisible Wall: Kubernetes Scaling Limits
- API Server: Choked by too many watchers; leads to latency and failed requests
- etcd: Overloaded with objects and writes; compaction and watch lag follow
- Controller Manager: Falls behind; rollouts and reconciliations stall
- Kubelet: Status noise and cgroup pressure degrade node stability
- CoreDNS: DNS bloat causes resolution timeouts
- kube-proxy: Large rulesets and conntrack exhaustion drop traffic
The Ripple Effect: Broader Operational Challenges
- Process Overload: Platform teams impose restrictive policies for security, often at the cost of developer velocity and autonomy
- Upgrades: Cluster-wide upgrades become high-risk, time-consuming operations that require careful coordination, extensive testing, and scheduled downtime to avoid disrupting critical workloads.
- Misconfigurations: One single team misconfiguration can impact everyone else running on the cluster.
- Debugging: Troubleshooting issues in a massive, shared environment is complex and noisy, with overlapping logs, metrics, and policies.
- Blast Radius: As more tenants and teams share the same cluster, the impact of any failure or breach scales proportionally, turning localized problems into full-platform incidents.
Security and Isolation: Avoiding 'Friendly Fire' in Shared Clusters
- Flat trust domain: One compromise can affect all workloads
- RBAC sprawl: Overprivileged accounts linger
- Network policy overlap: Accidental exposure between teams
- Noisy neighbors: Resource exhaustion spills across workload
Many teams let these problems creep in, or actively ignore them, not because they don’t care, but because they don’t see a viable alternative. The idea of securely connecting multiple clusters often feels out of reach, riddled with DNS hacks, overlapping IP ranges, and fragile VPN tunnels. So instead of solving the real problem—how to network across clusters cleanly—they just keep piling more into a single one.
In most cases, the reason multi-cluster isn’t adopted isn’t operational overhead. It’s networking: how do you route traffic across trust boundaries? How do you manage service discovery and DNS without brittle hand-offs? Without a solid answer, teams choose the path of least resistance: one cluster, one network, one growing mess.
Treat Clusters as Cattle, Not Pets
Treating clusters as cattle, not pets, means designing them to be disposable, consistent, and purpose built, rather than fragile, inflexible monoliths. A multi-cluster approach improves fault isolation, simplifies security boundaries, and allows teams to scale independently without impacting the entire platform. Of course, you need tools for cross-cluster communication and policy, but that’s how you build cleaner, more resilient architectures.
This is exactly where Gloo Mesh with Ambient Mesh comes in. It removes the heavy lifting of multi-cluster networking and tenancy by providing a secure, transparent data plane across clusters. Workloads in every cluster communicate over mTLS by default, both within and across cluster boundaries. They have strong identities that allow you to create policies that span cluster boundaries. Service discovery is peered automatically, so apps don’t need to know (or care) which cluster they or their dependencies live in.
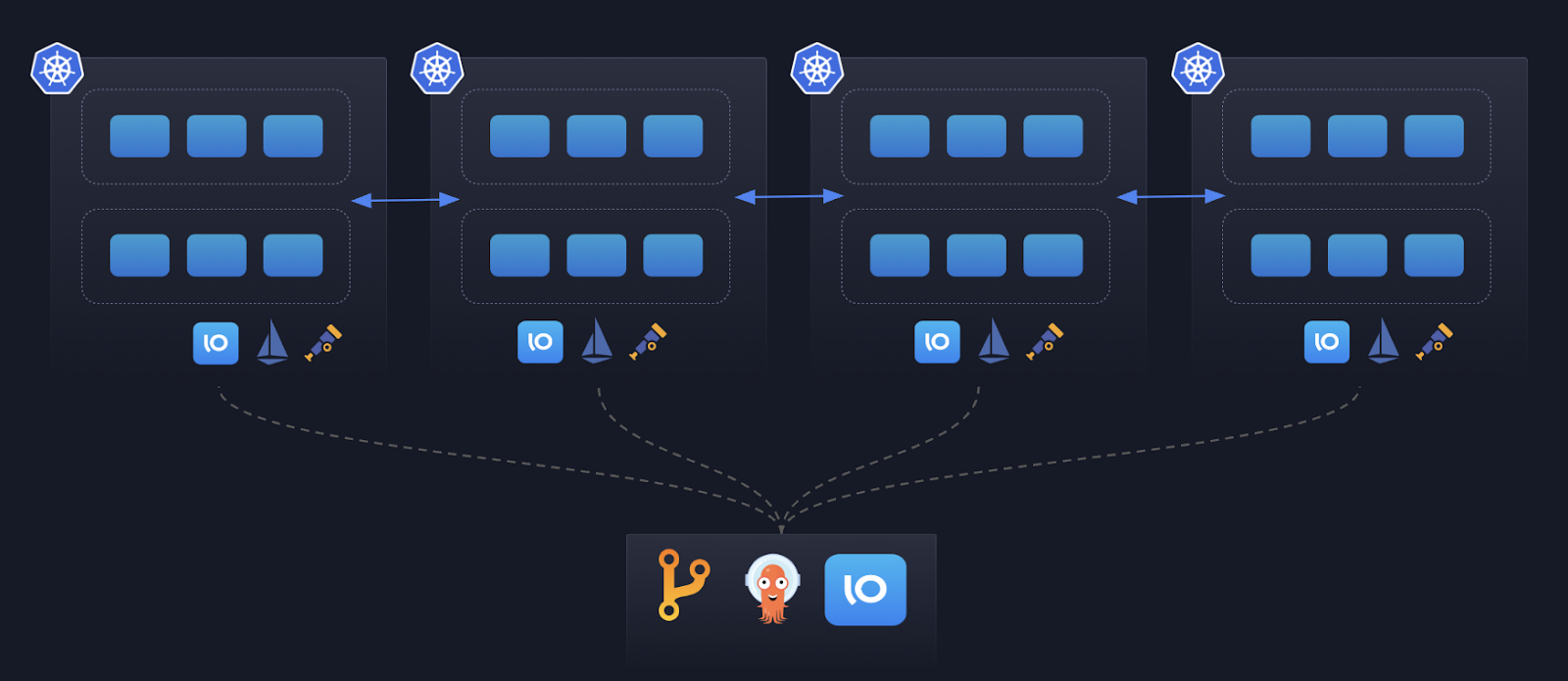
The key components of this architecture include:
Service Discovery: Working closely with the local Kubernetes API, the istio control plane (istiod) in every cluster peer with one another efficiently sharing service discovery information for services that should be globally accessible.
Uniform Identity: Istio issues each pod a strong SPIFFE identity rooted in a shared trust domain across clusters. This ensures that workloads can securely authenticate and authorize communication no matter where they run, without relying on brittle IP-based rules. It enables consistent enforcement of policies, regardless of where workloads are running.
Central Observability: Using a standard like OpenTelemetry allows teams to collect metrics, traces, and logs uniformly across all clusters and send to a unified location. This makes it possible to visualize traffic flow and performance in a single dashboard, again, regardless of where workloads are running.
In the following video, Louis Ryan, CTO of Solo.io, discusses why service mesh is suited to solve complex networking problems at massive, enterprise scale. He shares various patterns and learnings gained from architecting and deploying Ambient mesh alongside our customers.
With this foundation, teams can finally treat clusters as flexible building blocks rather than fragile silos. They can segment by environment, team, geography, or trust domain - all without sacrificing connectivity, observability, or security. The result? Cleaner architectures, smaller blast radius, and a platform that scales without cracking.
To learn more, check out these resources:
- Service Mesh at Scale: Download this eBook to learn more about service mesh and the best approaches (and challenges) to multi-cluster deployment patterns
- Scale beyond 1 Million Pods: Introducing Gloo Mesh Ambient Multicluster: Read the blog by John Howard on how Gloo Mesh extends Ambient Mesh








%20(1).png)




















%20a%20Bad%20Idea.png)








