

When we first started building kagent, we didn't run every agent in its own Kubernetes Pod, Service, and ServiceAccount. Instead, agents were simply executed inside the kagent runtime. It was the simplest architecture possible: one runtime hosting many agents.
It worked well for demo and proof-of-concepts.
As the number of agents grew, however, fundamental questions started to emerge.
- How do we isolate one agent from another?
- How does each agent get its own identity?
- How do we enforce access and network policies?
- How do we understand what an individual agent is doing?
- Who owns an agent, and how do we support multi-tenancy?
These aren't Kubernetes questions. They're agent platform questions.
The Pod as the Deployment Unit
Our first answer was straightforward: run every agent in its own Pod, Service, and ServiceAccount.
That decision immediately solved many of our problems.
A Pod provides process and container isolation. A ServiceAccount gives every agent its own Kubernetes identity, allowing us to integrate naturally with authentication and authorization mechanisms. Existing network policies, admission policies, and security controls continue to work without modification. Observability systems can attribute logs, metrics, and traces to individual agents. Scheduling and resource management also became Kubernetes-native.
As the architecture evolved, we introduced stronger isolation mechanisms such as agent-sandbox in kagent, allowing agents to execute with tight security boundaries.
For a while, this felt like the right abstraction.
But Should Agents Be Best Represented as Pods?
The more we thought about agents, the more we realized they are quite different from traditional microservices.
Most services are expected to be continuously available.
Agents are not.
An agent may wake up only when assigned a task, execute for a few seconds or minutes, and then become completely idle. Keeping a dedicated Pod alive for every potential agent quickly becomes wasteful.
Agents also have execution patterns that don't resemble long-running services:
- An agent may dynamically create multiple subagents to perform certain subtasks in parallel.
- An agent may impersonate a user or execute on behalf of a human.
- An agent may pause while waiting for human approval before continuing.
- An agent's lifetime may be measured in seconds or minutes rather than days.
These characteristics naturally lead to a question:
Are Kubernetes Pods the right lifecycle abstraction for short-lived, bursty AI agents?
Pods are excellent execution environments. But that doesn't necessarily mean they should also be the right abstraction for AI agents.
Enter Agent-substrate
Instead of treating every agent as a first-class Kubernetes workload, agent-substrate introduces an additional control plane above Kubernetes. Kubernetes continues to manage Pods, Services, networking, storage, and compute resources, while agent-substrate manages the lifecycle and placement of AI actors onto execution workers.
Agent-substrate introduces a set of abstractions that are similar to the Kubernetes concepts we are already familiar with. A WorkerPool is analogous to a NodePool, Workers are analogous to Nodes, and ActorTemplate corresponds to the declarative specification of a Pod.
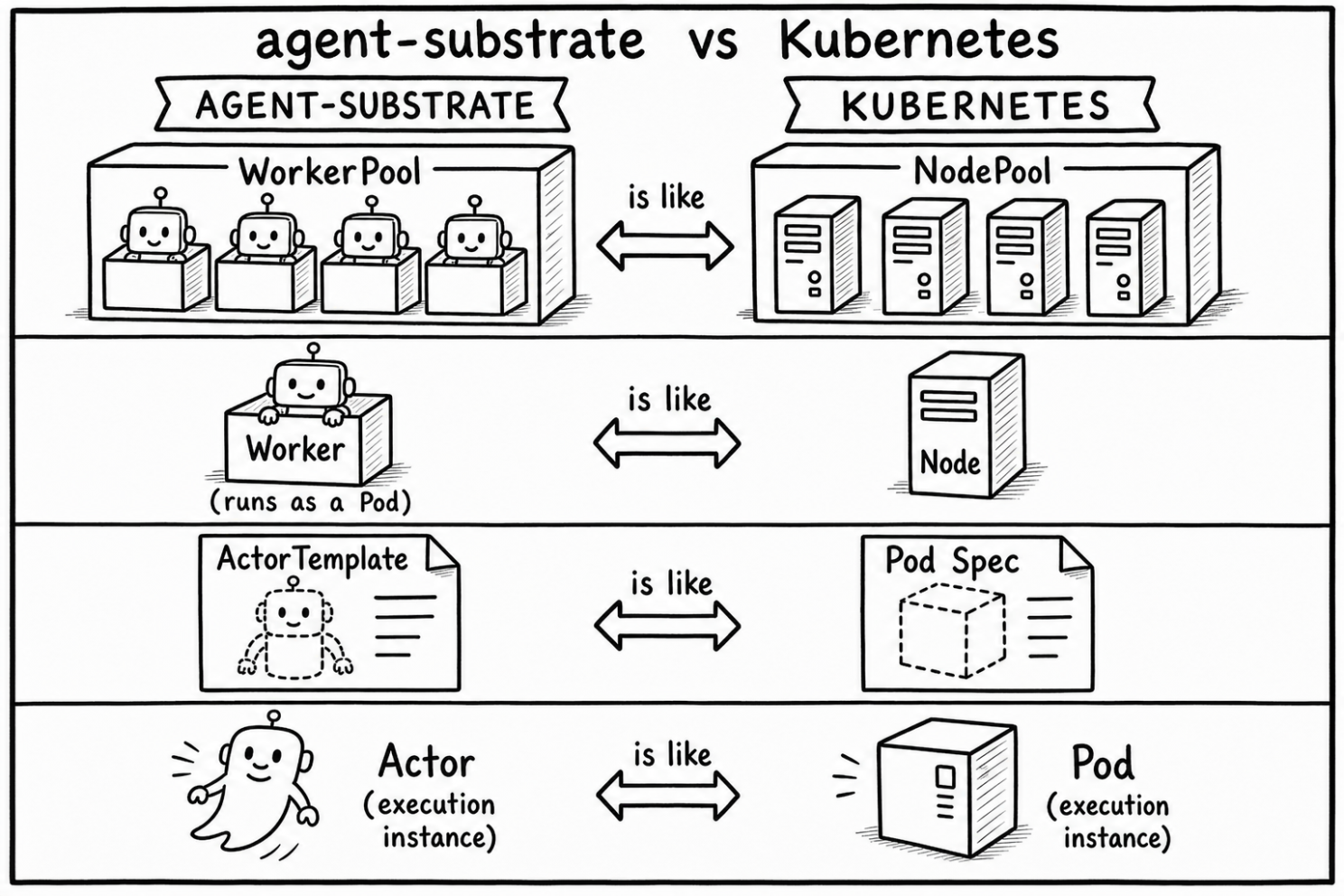
Let's look at what this abstraction looks like in practice. A WorkerPool defines a collection of execution workers that can host Actors. Example of the default WorkerPool in kagent:
apiVersion: ate.dev/v1alpha1
kind: WorkerPool
metadata:
labels:
app.kubernetes.io/instance: kagent
app.kubernetes.io/name: kagent
name: kagent-default
namespace: kagent
spec:
ateomImage: ghcr.io/kagent-dev/substrate/ateom-gvisor:v0.0.6
replicas: 3
An ActorTemplate defines how an Actor should execute, much like a PodTemplate defines how a Pod should be created. Below is an example of a simple ActorTemplate in kagent. Note that it includes the runsc configuration, which serves as the execution entrypoint for gVisor. I omitted several kagent-specific fields, including the agent’s name and additional configuration details.
apiVersion: ate.dev/v1alpha1
kind: ActorTemplate
metadata:
labels:
app.kubernetes.io/managed-by: kagent
kagent.dev/sandbox-agent: hello-substrate
name: hello-substrate
namespace: kagent
spec:
containers:
- command:
- /app
...
env:
...
image: cr.kagent.dev/kagent-dev/kagent/golang-adk@sha256:e01479b52280b0eae9e2808cc68392ba98fd737782496ff256847257e6bb8ed1
name: kagent
pauseImage: gcr.io/gke-release/pause@sha256:bcbd57ba5653580ec647b16d8163cdd1112df3609129b01f912a8032e48265da
runsc:
amd64:
sha256Hash: efd12935f6654c91a1389710eb8dfa4d12b6b9be00db87526dc2eb584ad00119
url: gs://gvisor/releases/nightly/2026-06-02/x86_64/runsc
arm64:
...
snapshotsConfig:
location: gs://ate-snapshots/kagent/hello-substrate
workerPoolRef:
name: kagent-default
namespace: kagent
The Worker or Actor is not represented as a custom resource in Kubernetes. Kubernetes only sees WorkerPools and ActorTemplates. Agent-substrate, however, sees Workers and Actors. This separation allows the cluster to manage a fixed number of execution Pods while agent-substrate manages a much larger number of logical agents. You can use the substrate CLI or API to view them directly. Each Worker is mapped to a single unique Pod.
$ kubectl-ate get workers
NAMESPACE POOL POD STATUS ASSIGNED ACTOR
kagent kagent-default kagent-default-deployment-ddfcfbdd7-54pb7 FREE <none>
kagent kagent-default kagent-default-deployment-ddfcfbdd7-jmjl5 FREE <none>
kagent kagent-default kagent-default-deployment-ddfcfbdd7-z2mmh FREE <none>
$ kubectl-ate get actors
NAMESPACE TEMPLATE ID STATUS ATEOM POD ATEOM IP VERSION
kagent hello-substrate a786a0c4-c2c8-44e5-9ea5-67b64f41deb1 STATUS_SUSPENDED <none> 5
kagent hello-substrate asr-kagent-hello-substrate-019efbb5-cc48-7601-8fc6-985e6239aa05 STATUS_SUSPENDED <none> 5
kagent hello-substrate-linsun 0c82223d-cc14-40c8-a25c-5ee00fe153ae STATUS_SUSPENDED <none> 5
kagent hello-substrate-linsun3 asr-ce96fc0ee592bf1e12336461 STATUS_SUSPENDED <none> 5
The important distinction is that an Actor, which represents("acts as") an AI agent, is no longer itself a Kubernetes Pod.
Instead, an Actor is a logical entity that can be scheduled onto an agent-substrate Worker when work arrives and removed when execution completes. Workers remain long-running Pods managed by Kubernetes, while Actors are lightweight execution units that share those workers.
This abstraction allows us to continue leveraging Kubernetes for pods and services scheduling, networking, security, and resource management while supporting far more AI agents than the cluster could ever support as individual Pods.
In other words, Pods become the execution workers, not the deployment model for agents.
Challenging More Than Deployment Model
At first glance, agent-substrate may look like a more efficient scheduling layer.
In reality, it challenges a much deeper assumption: should a Pod be the primary representation of an AI agent at all?
Agent Identity
Should an agent's identity really be tied to a Pod or its Service?
Or should identity belong to the ActorTemplate, namespace, tenant, and version, independent of whichever Worker happens to execute the Actor at a given moment? Christian Posta tried to explore this topic much deeper in his blog.
Security and Policy
Today, Kubernetes policies are attached to Pods, Services, or ServiceAccounts.
Should access control, network policy, and runtime permissions instead be expressed at the ActorTemplate level and selectively overridden for individual Actors? Can we use agentgateway to mediate the traffic and enforce policies?
Ownership and Multi-tenancy
Who owns an Actor?
Who owns an ActorTemplate?
How are quotas, billing, and lifecycle managed across teams and tenants when AI agent execution is no longer tied one-to-one with Pods?
Observability
When an Actor executes on different Workers over its lifetime, observability must follow the logical agent, not the underlying Pod.
Logs, traces, audit records, and execution history should all be associated with the Actor regardless of where it was scheduled.
Looking Ahead
Kubernetes remains an exceptional platform for running microservices and inference workloads at scale.
But AI agents introduce more unique characteristics than traditional cloud-native services. They are ephemeral, bursty, capable of spawning subagents on demand, and often act on behalf of users. The Pod may still be the right execution unit for AI agents, but it may no longer be the right deployment, identity, or lifecycle unit.
That is the question agent-substrate is exploring. Explore the agent-substrate project through kagent, join the agent-substrate community, and feel free to connect with author Lin Sun on LinkedIn.








%20(1).png)




















%20a%20Bad%20Idea.png)








