eBPF for Service Mesh? Yes, but Envoy Proxy is here to stay
Our goal here at Solo.io is to bring valuable solutions to our customers around application networking and service connectivity. Back in October, we announced our plans to enhance our enterprise service-mesh product (Gloo Mesh Enterprise) with eBPF to optimize the functionality around networking, observability, and security. To what extent can eBPF play a role in a service mesh? How does the role of the service proxy change? In this blog we will dig into the role of eBPF for a service mesh data plane and what are some of the tradeoffs of various data-plane architectures.
Goodbye to the service proxy?
A service mesh provides complex application-networking behaviors for services such as service discovery, traffic routing, resilience (timeout/retry/circuit breaking), authentication/authorization, observability (logging/metrics/tracing) and more. Can we rewrite all of this functionality into the Kernel with eBPF?
The short answer: this would be quite difficult and may not be the right approach. eBPF is an event-handler model that has some constraints around how it runs. You can think of the eBPF model as “functions as a service” for the Kernel. For example, eBPF execution paths must be fully known and verified before safely executing in the Kernel. eBPF programs cannot have arbitrary loops where the verifier will not know when the program will stop execution. In short, eBPF is Turing incomplete.
Layer 7 handling (like various protocol codecs, retries, header manipulations, etc) can be very complex to implement in eBPF alone and without better native support from the Kernel. Maybe this support comes, but that is likely years off and wouldn’t be available on older versions. In many ways, eBPF is ideal for O(1) complexity (such as inspecting a packet, manipulating some bits, and sending it on its way). Implementing complex protocols like HTTP/2 and gRPC can be O(n) complexity and very difficult to debug. So where could these L7 functionalities reside?
Envoy proxy has become the de-facto proxy for service mesh implementations and has very good support for Layer 7 capabilities that most of our customers need. Although eBPF and the Kernel can be used to improve the execution of the network (short circuiting optimal paths, offloading TLS/mTLS, observability collection, etc), complex protocol negotiations, parsing, and user-extensions can remain in user space. For the complexities of Layer 7, Envoy remains the data plane for the service mesh.
One shared proxy vs sidecar proxies?
Another consideration when attempting to optimize the data path for a service mesh is whether to run a sidecar per workload or to use a single, shared proxy per node. For example when running massive clusters with hundreds of pods and thousands of nodes, a shared-proxy model can deliver optimizations around memory and configuration overhead. But is this the right approach for everyone? Absolutely not. For many enterprise users, some memory overhead is worth the better tenancy and workload isolation gains with sidecar proxies.
Both architectures come with their benefits and tradeoffs around memory and networking overhead, tenancy, operations, and simplicity, and both can equally benefit from eBPF-based optimization. These two are not the only architectures, however. Let’s dig into the options we have along the following dimensions:
- Memory / CPU overhead – Configuring the routing and cluster details for an L7 proxy consists of proxy-specific configurations which can be verbose; the more services with which a particular workload needs to communicate, the more configurations it will need.
- Feature isolation – Applications are finicky and tend to need per-workload optimizations of connection pools, socket buffers, retry semantics/budgets, external-auth, and rate limiting. We see a lot of need for customizing the data path which is why we’ve introduced Wasm extensions. Debugging these features and behaviors also becomes demanding. We need to figure out a way to isolate these features between workloads.
- Security granularity – A big part of the zero-trust philosophy is to establish trust to peers at runtime based on current context; scoping these trust boundaries as small as possible is usually desirable.
- Upgrade impact – A service mesh is incredibly important infrastructure since it’s on the request path; we need to have very controlled upgrades of service-mesh data-plane components to minimize outages
Let’s look at four possible architectures where eBPF is used to optimize and short-circuit the network paths and leverage Envoy proxy for Layer 7 capabilities. For each architecture, we evaluate the benefits and tradeoffs of where to run the Layer 7 proxy along the lines of overhead, isolation, security, and upgrades.
Sidecar proxy (service proxy)
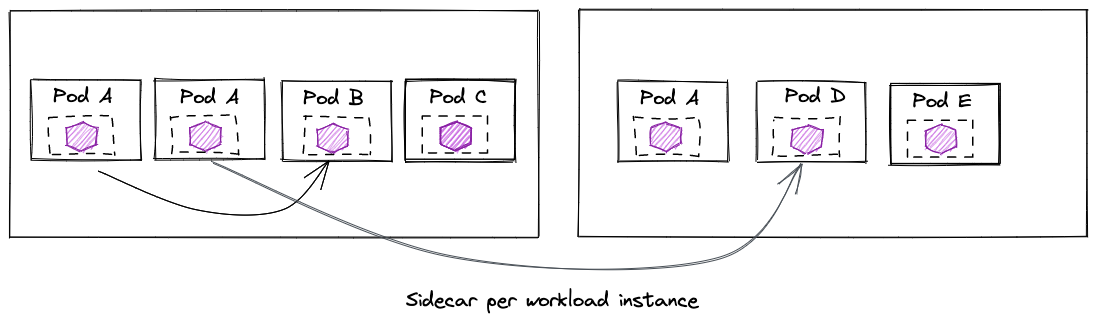
In this model, we deploy a sidecar proxy with each application instance. The sidecar has all of the configurations it needs to route traffic on behalf of the workload and can be tailored to the workload.
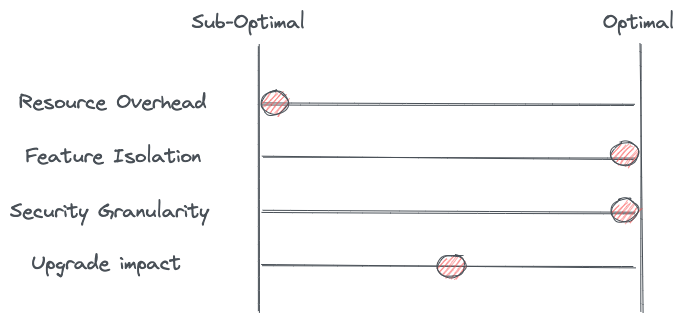
With many workloads and proxies, this configuration is duplicated across workload instances and can present a “sub-optimal” amount of resource overhead.
This model does give the best feature isolation to reduce the blast radius of any noisy neighbors. Misconfigured or app-specific buffers/connection-pooling/timeouts are isolated to a specific workload. Extensions using Lua or Wasm (that could potentially take down a proxy) are also constrained to specific workloads.
From a security perspective, we originate and terminate connections directly with the applications. We can use the mTLS capabilities of the service mesh to prove the identity of the services on both ends of the connections scoped down to the level of the application process. We can then write fine-grained authorization policies based on this identity. Another benefit of this model comes if a single proxy ends up victim to an attacker, the compromised proxy is isolated to a specific workload; the blast radius is limited. On the downside, however, since sidecars must be deployed with the workload, there is the possibility that a workload opts not to inject the sidecar, or worse, finds a way to work around the sidecar.
Lastly, in this model, upgrades can be done per workload and follow a canary approach that affects only specific workloads. For example, we can upgrade Pod A’s data plane to a new version without affecting any of the other workloads on the node. The downside to this is injecting the sidecar is still tricky and if there are changes between versions, it could affect the app instance.
Shared proxy per node
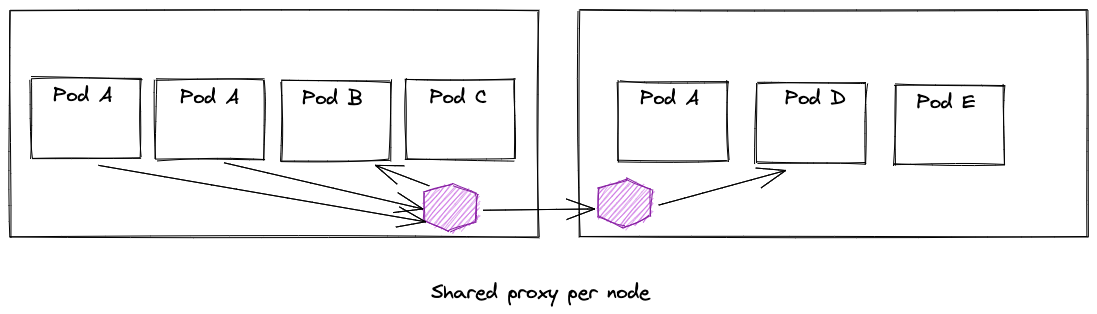
The shared-proxy per node introduces optimizations that make sense for large clusters where memory overhead is a top concern and amortization of the cost of the memory is desirable. In this model, instead of each sidecar proxy configured with the routing and clusters needed to route traffic, that configuration is shared across all workloads on a node in a single proxy.
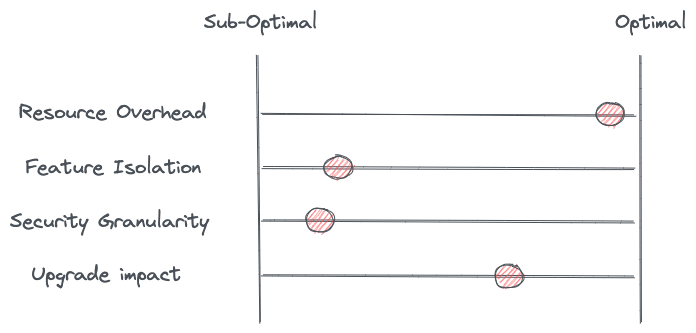
From a feature isolation perspective, you end up trying to solve all of the concerns for all of the workload instances in one process (one Envoy proxy) and this can have drawbacks. For example, could application configurations across multiple apps conflict with each other or have offsetting behaviors in the proxy? Can you safely load secrets or private-keys that must be separated for regulatory reasons? Can you deploy Wasm extensions without the risk of affecting the behavior of the proxy for other applications? Sharing a single proxy for a bunch of applications has isolation concerns that could potentially be better solved with separate processes/proxies.
Security boundaries also become shared in the shared-proxy per-node model. For example, workload identity is now handled at the node level and not the actual workload. What happens for the “last mile” between the proxy and the workload? Or worse, what happens if a shared proxy representing multiple workload identities (hundreds?) is compromised?
Lasly, upgrading a shared proxy per node could affect all of the workloads on the node if the upgrade has issues such as version conflicts, configuration conflicts, or extension incompatibilities. Any time shared infrastructure handling application requests is upgraded, care must be taken. On the plus side, upgrading a shared-node proxy does not have to account for any of the complexities of injecting a sidecar.
Shared proxy per service account (per node)
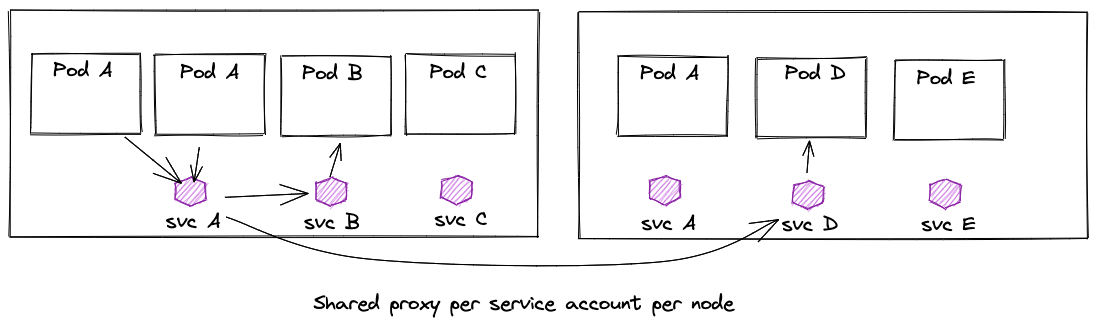
Instead of using a single shared proxy for the whole node, we can isolate proxies to a specific service account per node. In this model, we deploy a “shared proxy” per service account/identity, and any workload under that service account/identity uses that proxy. We can avoid some of the complexities of injecting a sidecar with this model.
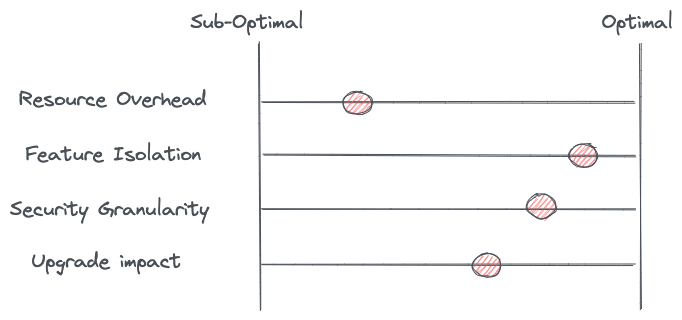
This model tries to save memory in scenarios where multiple instances of the same identity are present on a single node and maintains some level of feature and noisy-neighbor isolation. This model has the same advantages of a sidecar for workload identity, however it does come with the drawbacks of a shared proxy: what happens to the last mile connections? How is authentication established all the way back to the workload instance? One thing we can do to improve this model is use a smaller “micro proxy” that lives with the application workload instances that can facilitate end-to-end mTLS down to the instance level. Let’s see that in the next pattern.
Shared remote proxy with micro proxy
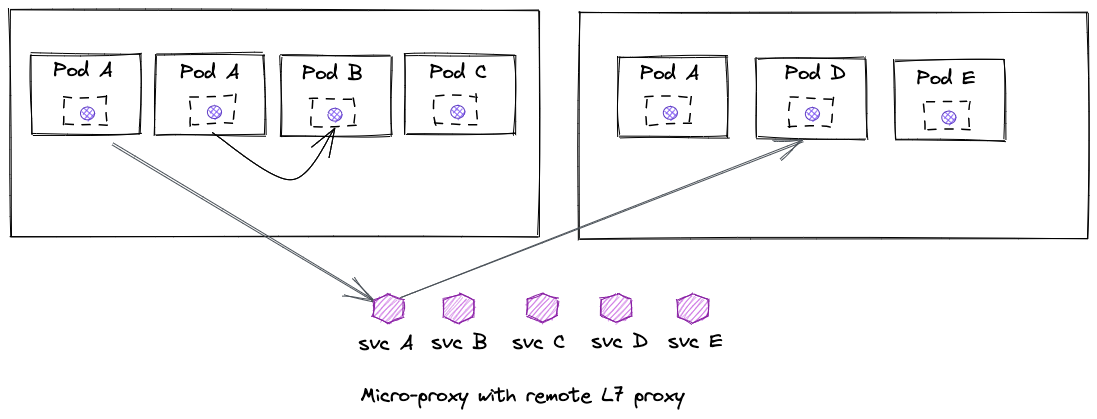
In this model, a smaller, lightweight “micro proxy” (uProxy) that handles only mTLS (no L7 policies, smaller attack surface) is deployed as a sidecar with the workload instances. When Layer 7 policies need to be applied, traffic is directed from the workload instance through the Layer 7 (Envoy) proxy. The Layer 7 proxy can run as a shared-node proxy, per-serviceaccount, or even a remote proxy. This model also allows completely bypassing the Layer 7 proxy when those policies may not be needed (but keeping mTLS origination/negotiation/termination with the application instances.
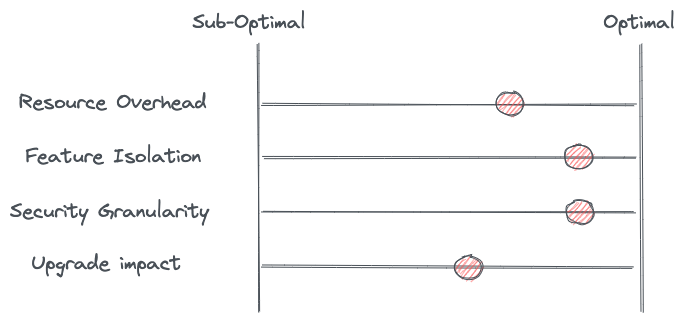
This model reduces the configuration overhead of Layer 7 policies you see in sidecars but could introduce more hops. These hops may (or may not) contribute to more call latency. It’s possible that, for some calls, the L7 proxy is not even in the data path which would improve call latency.
This model combines the sidecar proxy benefits of feature isolation and security since the uProxy is still deployed with the workload instances.
From an upgrade standpoint, we can update the L7 proxy transparently to the application, however we now have more moving pieces. We need to also coordinate the upgrade of the uProxy which has some of the same drawbacks as the sidecar architecture we discussed as the first pattern.
Parting thoughts
As discussed in “The truth about the service mesh data plane” back at Service Mesh Con 2019, architectures representing the data plane can vary and have different tradeoffs. At Solo.io, we see eBPF as a powerful way to optimize the service mesh, and we see Envoy proxy as the cornerstone of the data plane. Working with our many customers (of various sizes, including some of largest deployments of service mesh in the world), we are in a unique position to help balance the tradeoffs between optimizations, features, extensibility, debuggability and user experience.


