Configuration as Data, GitOps, and Controllers: it’s not simple for multi-cluster
One big benefit of using a declarative configuration approach, or “configuration as data” as Kelsey Hightower says, is understanding the intent of the desired end state of a system. Declarative configuration becomes a contract between users/tools and makes it easy to understand whether the system is in the desired state or not. Kubernetes is an example of a system that uses declarative configuration to drive system state. With Kubernetes, you specify objects like Deployments or Services, then controllers read the declarative configuration and use reconciliation loops to converge on the desired end state.
GitOps is a way to define workflows for declarative configuration using Git. See this excellent article from Weaveworks describing GitOps. With GitOps, we define our expected system (for example, a Kubernetes cluster) end state in declarative configuration, store it in Git, and follow a pull-request workflow for changes which are then tracked and audited. How do controllers fit into this workflow?
As discussed in Operators in a GitOps world between Christian Hernandez and Chris Short there is a “point of demarcation” between the responsibility of a controller and what should be specified in a Git repo for a GitOps workflow. Some definitions of GitOps refer to storing the “entire desired state of the whole system” and leave much to interpretation. If the entire state of a system can be driven from Git, does it matter which controllers exist if the end state eventually converges correctly?
It does matter. As we build more complicated systems, especially over multiple clusters, focus on the intent and verification of end state are first principles. Taking a naive approach will lead to outages, security vulnerabilities, or at the very least an unknown and unpredictable state. Let’s take a closer look.
A basic example of declarative configuration and controllers
Declarative configuration should specify the intent of the end state while controllers reconcile any divergent state. If the system is not in the intended state, controllers will detect the difference and make the necessary changes to fulfill the intent. Controllers may also be layered in stages (so one controller’s output is input to other controller) to accomplish the end state goal. Let’s look at a simple example:
apiVersion: apps/v1 kind: Deployment metadata: name: envoy-deployment labels: app: envoy spec: replicas: 3 strategy: RollingUpdate selector: matchLabels: app: envoy template: metadata: labels: app: envoy spec: containers: - name: nginx image: envoyproxy/envoy:v1.19.0 ports: - containerPort: 80
A Kubernetes Deployment describes the following intention:
- What application/container should be deployed
- How many replicas
- What the rollout strategy should be
When you apply this Deployment resource to a Kubernetes cluster, a controller responsible for Deployments will create a number of pods (also specified as declarative configuration called a Pod Spec) equal to the replicas setting in the configuration. If the state diverges at any point while the Deployment is active (ie, a pod gets killed for some reason), the Deployment controller will detect this change and spin up more pods to satisfy the intended state defined in the Deployment resource.
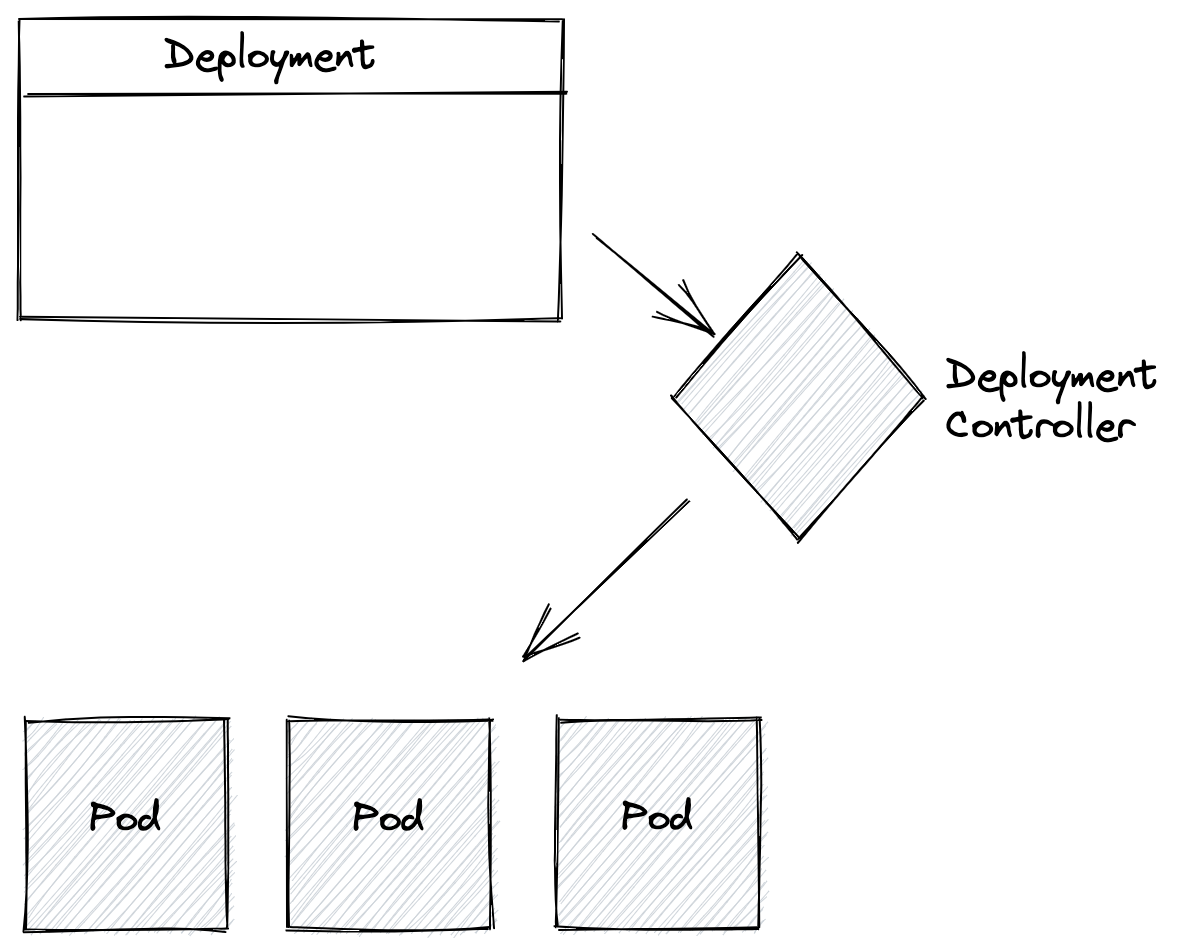
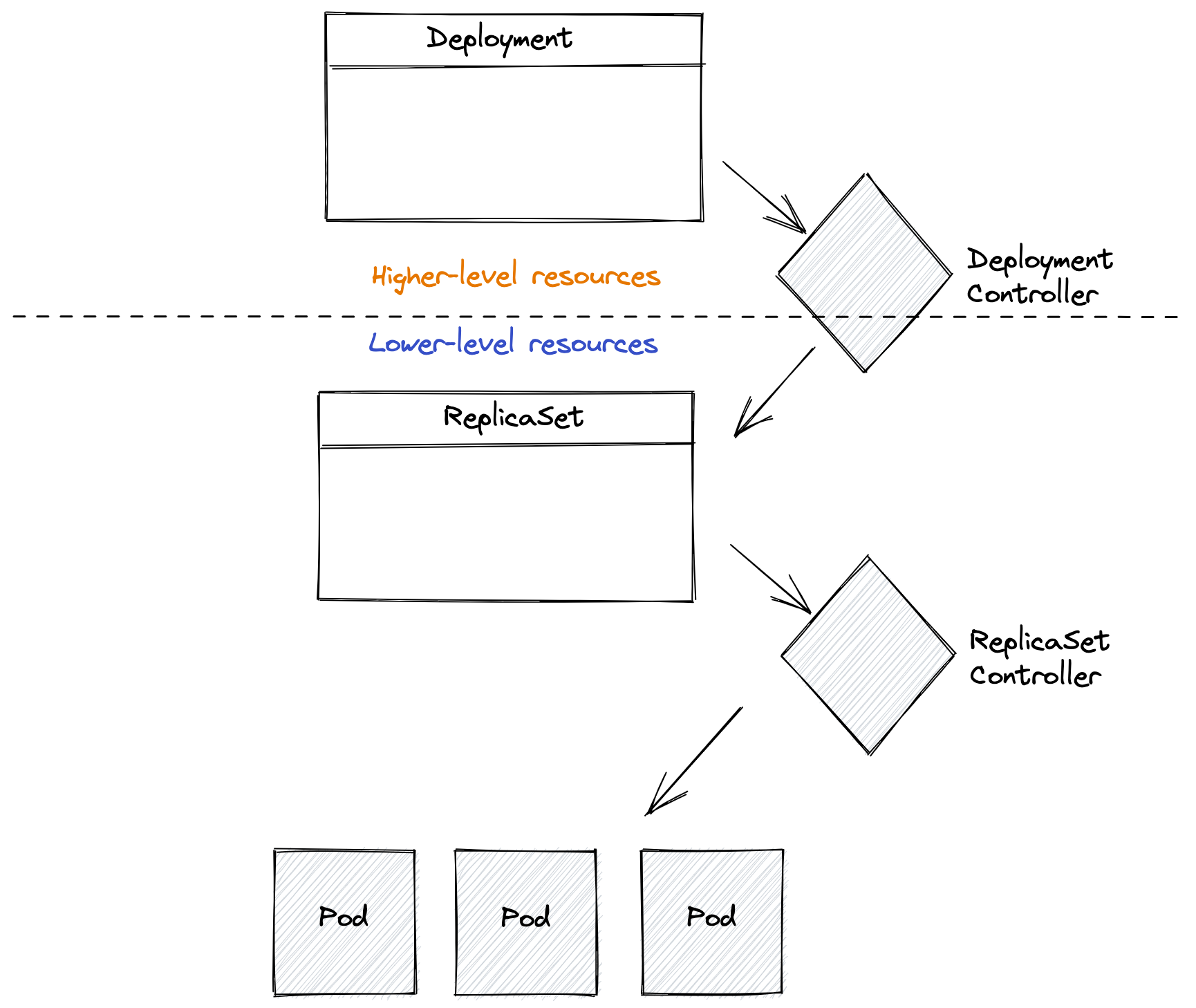
Actually, this isn’t entirely true. The Deployment resource is a higher-level declarative configuration, that when applied, causes the deployment controller to create other resources. In fact, it creates a ReplicaSet declarative resource which has its own controller to manage the number of replicas and which creates the lower-level Pod resources. As you can see, there can be layers of controllers which coordinate together to achieve the desired end state.
Extreme examples
I believe some people misinterpret the GitOps practice of “storing the desired state of the whole system” in Git especially when it comes to multiple clusters.
The responsibility of the controllers and how it fits with GitOps can be exaggerated to illustrate this point.
For example, could “storing desired state of whole system” mean don’t store any high-level configs and don’t rely on any controllers? That is, “don’t use any Deployment resources and just use Pod resources”? For example, you manage replicas and Pods yourself by specifying multiple Pod resources in your Git repo:
- pod-foo-1.yaml
- pod-foo-2.yaml
- pod-bar-3.yaml
- pod-bar-4.yaml
- …
- pod-wine-199.yaml
In this scenario, you are specifying every single detail of the system and not using any supporting controllers … Yeah, you could do this, but it will get very noisy very fast. What is the correct state of the system? How many “pod-foos” should there be? It gets very difficult to deduce because nowhere do we specify the intent of the system — ie, it gets lost in the noise.
What about the opposite extreme? What if we followed the example of the “high-level declarative configuration” of the Deployment resource and we create an even higher-level declarative configuration (using Kubernetes custom resources) and create controllers to orchestrate the creation of all the correct underlying resources (Deployments, Services, Ingress, etc).
apiVersion: foo.example.com/v1 kind: MyAbstractResource metadata: name: good-state spec: goodState: yes
You can see this is definitely a high-level resource. We could have a controller in the cluster that reads this resource and creates the following objects to satisfy the intent:
- 4 Deployments
- 7 Services
- 1 DaemonSet
- 1 Ingress resource
Clearly this one resource abstracts the intention away too much and may not be that useful. The trick is to achieve the right balance of intent and hide away any specific, possibly complex, operational concerns. Introducing multiple clusters can make this difficult. Let’s look at a real example from our experience building application-networking technology based on service mesh at Solo.io.
Case study: multi-cluster GitOps with Istio
All of our products at Solo.io use a declarative configuration + controller approach and lend themselves very nicely to GitOps. For our Gloo Mesh product, we’ve built a set of controllers that greatly simplify configuring and managing Istio Service Mesh at scale across multiple clusters. Let’s take a look at the problem that we solve and how it fits into this discussion.
Istio has its own custom resource definitions (CRDs) that constitute a declarative configuration model along with a controller that translates the declarative custom resources into configuration for its data plane (made up of Envoy proxies that run with each workload). This set of resources consist of, among others, resources for describing traffic routing rules (VirtualService), load balancing (DestinationRule), and configuration (Sidecar). There are also resources for extending Istio’s service discovery mechanism called ServiceEntry.
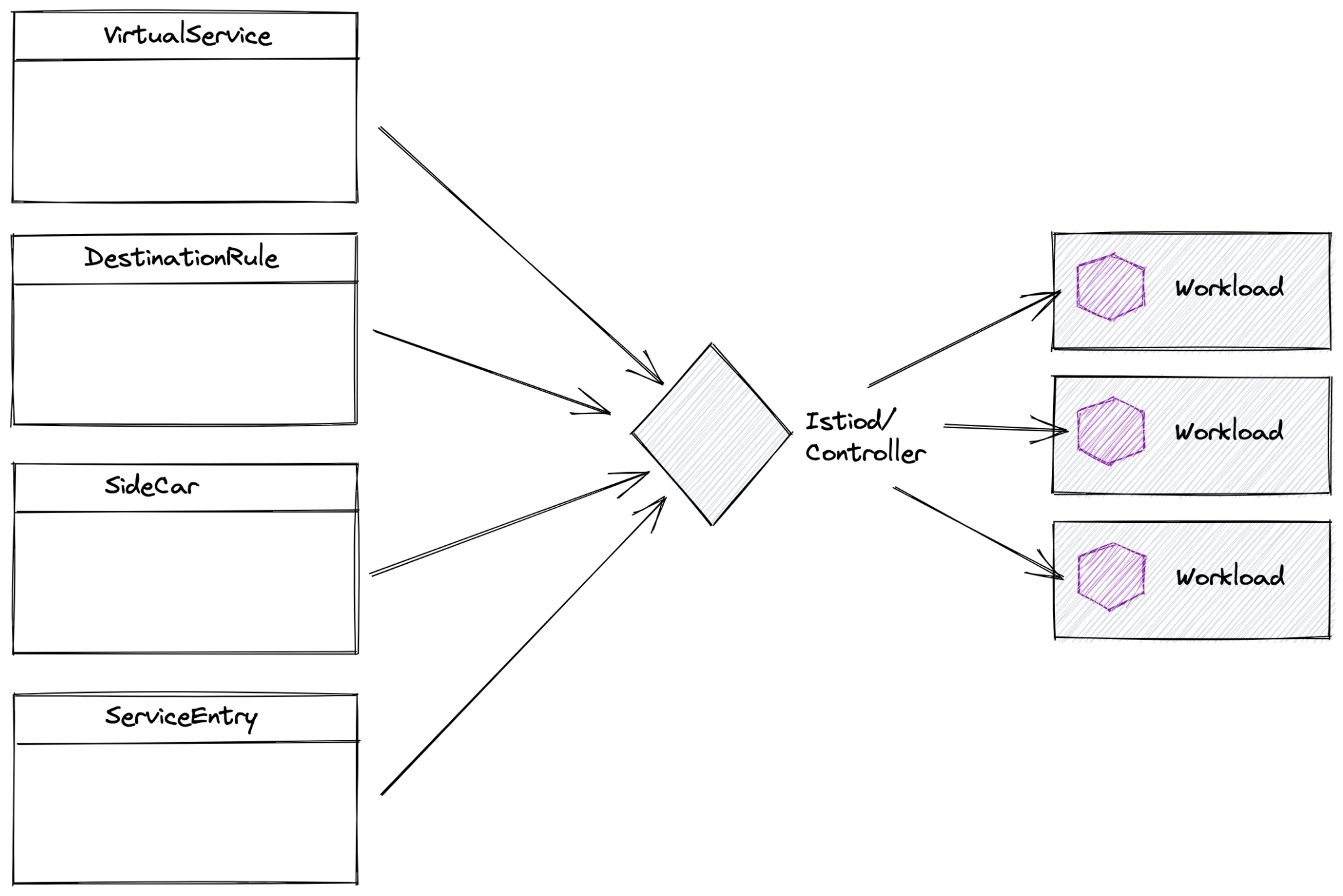
When our customers run Istio across multiple clusters, they don’t want these installations treated as completely independent boundaries; that is, services within a cluster should be able to communicate with services in other clusters via the mesh. Typical usecases that require this kind of cross-cluster communication include:
- services don’t run collocated in the same cluster so must cross cluster boundaries
- service traffic may need to failover to service dependencies in another cluster for high availability purposes
- a new version of a service (canary) is introduced in a separate (canary?) cluster and traffic should be routed there
- services on premises should call services running in a public cloud
- compliance, data locality, isolation reasons, etc
The problem we have to solve is how to federate Istio’s configuration across multiple clusters. But federation of configuration has been solved you say? The KubeFed project can do that, right? Or better yet, we can use GitOps to solve this problem but in a multi-cluster way, right?
Let’s take a look at where this breaks down.
Federating a service mesh has unique challenges
Using a federation engine like KubeFed or a multi-cluster GitOps approached as described in some recent blogs are predicated on either pushing the same exact configuration to more than one cluster, or simply storing all of the configurations for each cluster in Git and automatically pulling them into the respective clusters. This breaks down when the configurations are either
1) not exactly the same across all clusters
2) have intricate rules that are inter-cluster or inter-service dependent
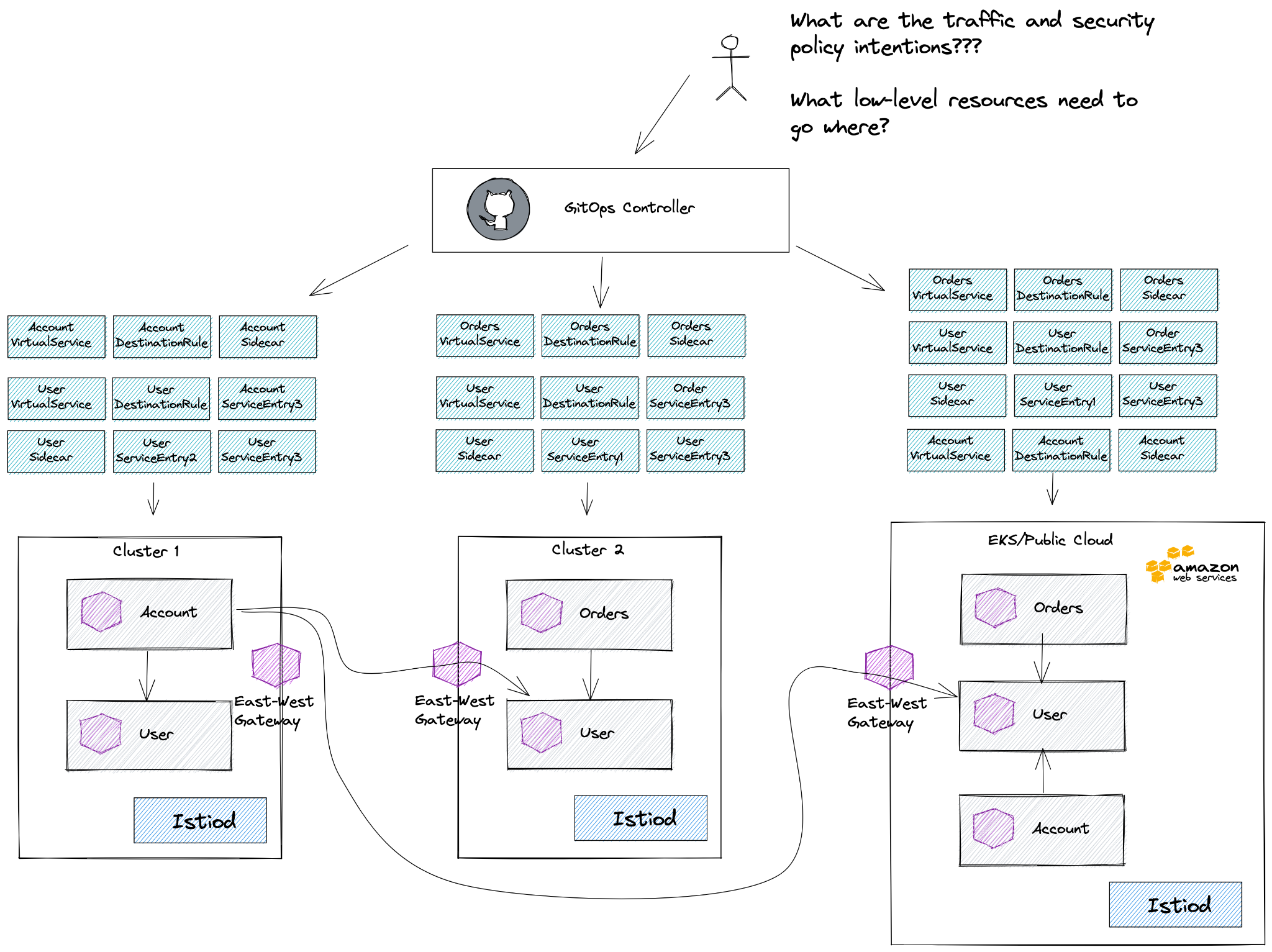
Let’s take an example running Istio across multiple clusters with our Gloo Mesh product. In the drawing below, you see three clusters running various workloads with one cluster running in the public cloud. The Account service talks to the User service in cluster 1, but what happens if the User service in cluster 1 starts to become overloaded or goes down for some reason? Ideally the Account service would transparently failover to the User service in another cluster, but which cluster? Is it based on locality? Priority? Maybe it should never failover to the instance deployed on a public cloud? The configuration for how a service fails over when it’s in cluster 1 would be different than if it was in cluster 2 or in the public cloud. These differences need to be accounted for somewhere and they should be explicit.
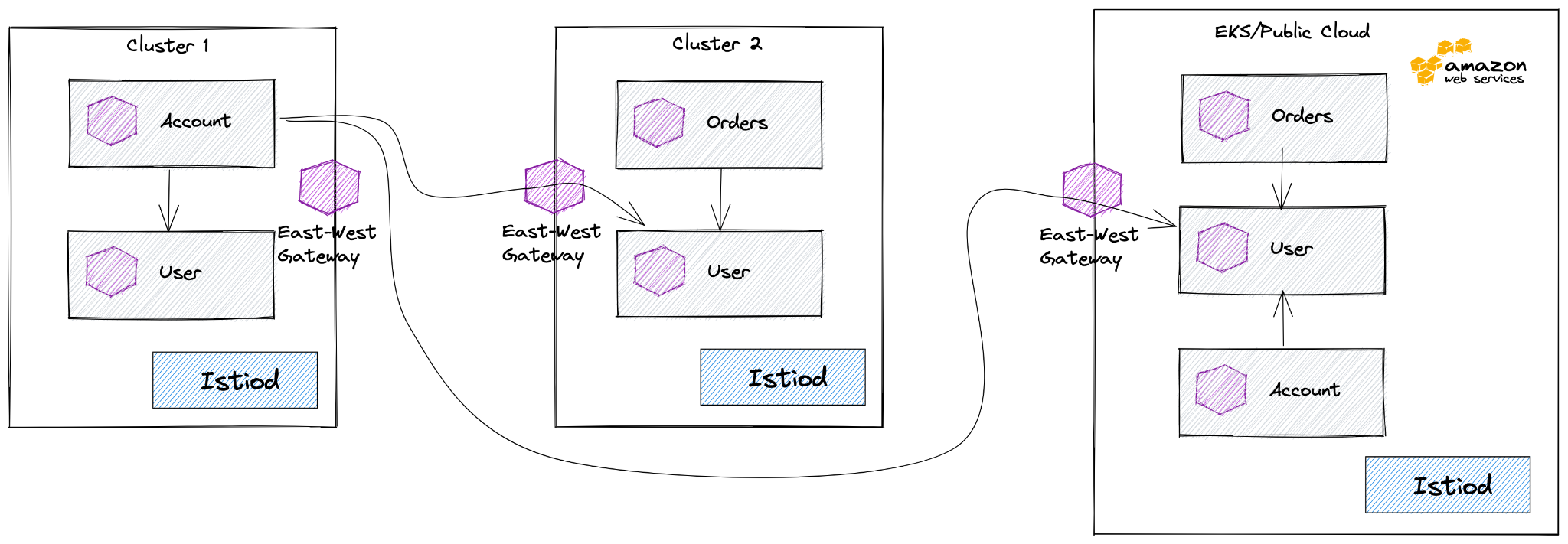
In Gloo Mesh we opt to federate multiple clusters by exposing services in remote clusters explicitly (the model suggested by the community has undesirable security posture for all of our customers). To do this, we create ServiceEntries on clusters only where they need to be. For example, in cluster 1 we create a ServiceEntry resource for the User service that lives in cluster 2 so that the Account service knows how to communicate cross-cluster to cluster 2 if it needs to fail over. We do not create a ServiceEntry in cluster 1 for the Order service since there are no services in that cluster that call the Order service. This scenario is an example of context aware (or cluster specific) service-dependency, and just like the previous scenario, this logic/smarts/context awareness needs to live somewhere and should be explicit.
The last example we see with multi-cluster management of Istio across clusters with Gloo Mesh is around security. In our example we want the Account service in the EKS cluster to call the User service, but we may not allow traffic from the Account service in the EKS cluster to the User service running “on premises” in cluster 2. Istio uses AuthorizationPolicy resources to configure identity-based authorizations and access. The AuthorizationPolicy resources that get deployed to the EKS cluster would necessarily be different than those deployed in cluster 2. This nuance has to be explicit and the knowledge or intention needs to live somewhere.
Here are some of the inter-cluster scenarios that would necessitate different configuration in different clusters for the service mesh:
- Dependency (ie, where to create service entries)
- Failover control (what endpoints are prioritized for failover, ie is it locality? is it priority?)
- Are there security concerns about failing over to a cluster in public cloud? or cloud to on premises?
- When traffic crosses clusters, are there more specific configurations (ie, keep alive)
- What happens if the cluster topology changes, need to reconcile — this out of the hands of operators at run time?
- region/locality/zone specific routing rules (ie, 20% of traffic from “foo” clusters for app “bar” should go to cluster “wine”
- canary clusters
- non homogeneous clusters
These nuances and their implications must be codified and live somewhere. Could you just use the lower-level Istio resources directly (VirtualService, DestinationRule, Gateway, ServiceEntry, AuthorizationPolicy, etc) for all of the various services that run in each cluster and manually specify their differences for each cluster and then put them into Git and deploy from there? Yeah. You could. But the overall intention of the traffic routing and security policies for availability, failover, compliance, etc will be lost in the noise of these low-level resources.
With Gloo Mesh, we’ve built a set of controllers and high-level APIs exactly for this reason: to abstract away a lot of the detail of the lower-level Istio resources and focus on the intention of the traffic and security postures. The Gloo Mesh TrafficPolicy resource specifies routing and resilience rules between services while the AccessPolicy resource specifies security rules. Another resource, the VirtualDestination, defines globally routable services. These higher-level resources are what should be stored into Git and applied to the Gloo Mesh management controllers. The Gloo Mesh management controllers run in a separate “meta” cluster that’s responsible for taking these higher-level resources and translating them to the correct lower-level Istio resources and orchestrating the configuration with the nuance, dependency, and context awareness to each cluster.
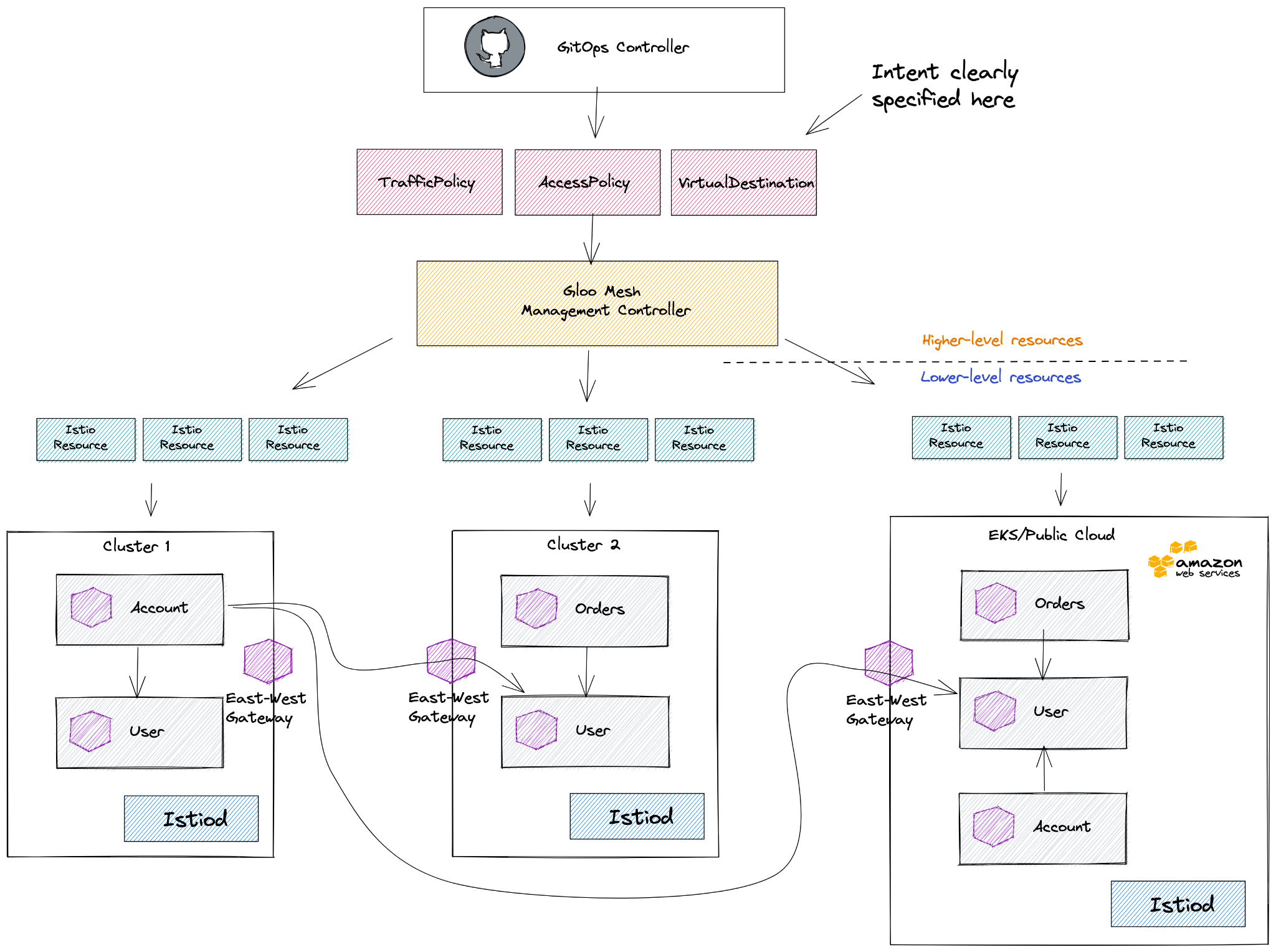
Additionally, the Gloo Mesh controllers are constantly watching the state of the clusters/workloads and constantly reconciling the lower-level resources (ie, if services are added, updated, moved, etc). This communication between the “meta” or configuration cluster and the “data plane” clusters is done via gRPC to an agent that runs in the remote clusters and handles applying any cluster-local configuration.
As you can see the Gloo Mesh controllers follow the sample principles as the higher-level controllers outlined earlier but they run outside any one specific cluster. They are responsible for translating and orchestrating the lower-level declarative configuration (Istio resources in this case) to each of the data plane clusters. The end-state intention is described in the higher-level declarative configuration (Gloo Mesh resources) and anyone looking at the system can more quickly determine what the end state is supposed to be. All of the complex dependency, directional, and security context nuance is coded in controllers that help eliminate human error.
Takeaways
Declarative configuration or “configuration as data” is a great practice for configuring dynamic, cloud systems based on intent and verifiable state. Getting the right “point of demarcation” is important and following first principles will help. Multi-cluster introduces some additional complexity, but the pattern is the same: focus on intent, and use a layer of controllers to reconcile the desired state even if those controllers span clusters. At Solo.io we have a lot of experience building these types of systems and have encoded a lot of operational best practices into our products. Reach out to us if you’re interested in enterprise/production support for Istio, Envoy, WebAssembly, or cloud-native API gateways.
